BYO SWE-grep: automatically train blazing fast search sub-agents on your knowledge base (Pt. 1)
RL-trained search subagents that learn your knowledge base’s structure for fast, reliable retrieval
Research
Nov 11, 2025
Case study
November 18, 2025
Purpose-built to capture emergency department nuance
Authors
Affiliations
Harry Partridge
Parsed
Charles O'Neill
Parsed
Emergency physicians spend 2-3 hours per shift on documentation. A particular company that builds ambient scribes that convert ED conversations into structured clinical charts came to us with a specific challenge: build a model that could handle the complexity of emergency medicine documentation while being fast enough for real-time use.
The task involves two stages. First, convert (often messy) ED transcripts into structured JSON with 16 distinct sections. Second, merge that JSON with physical exam templates to produce the final chart. Each stage has dozens of interlocking rules that must be followed precisely. This is quite scary, because getting things wrong means the model has introduced liability issues as well as just generating a bad note.
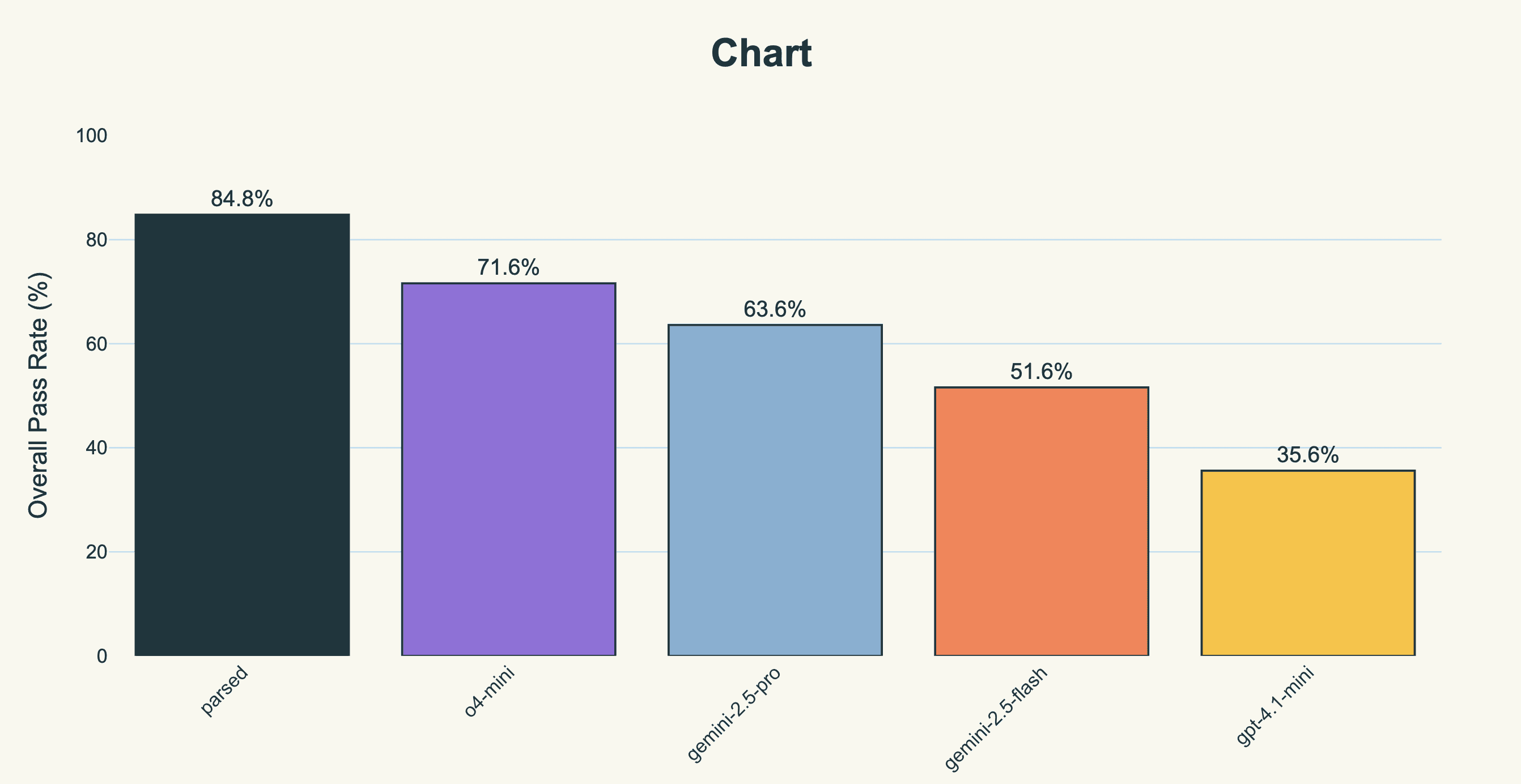
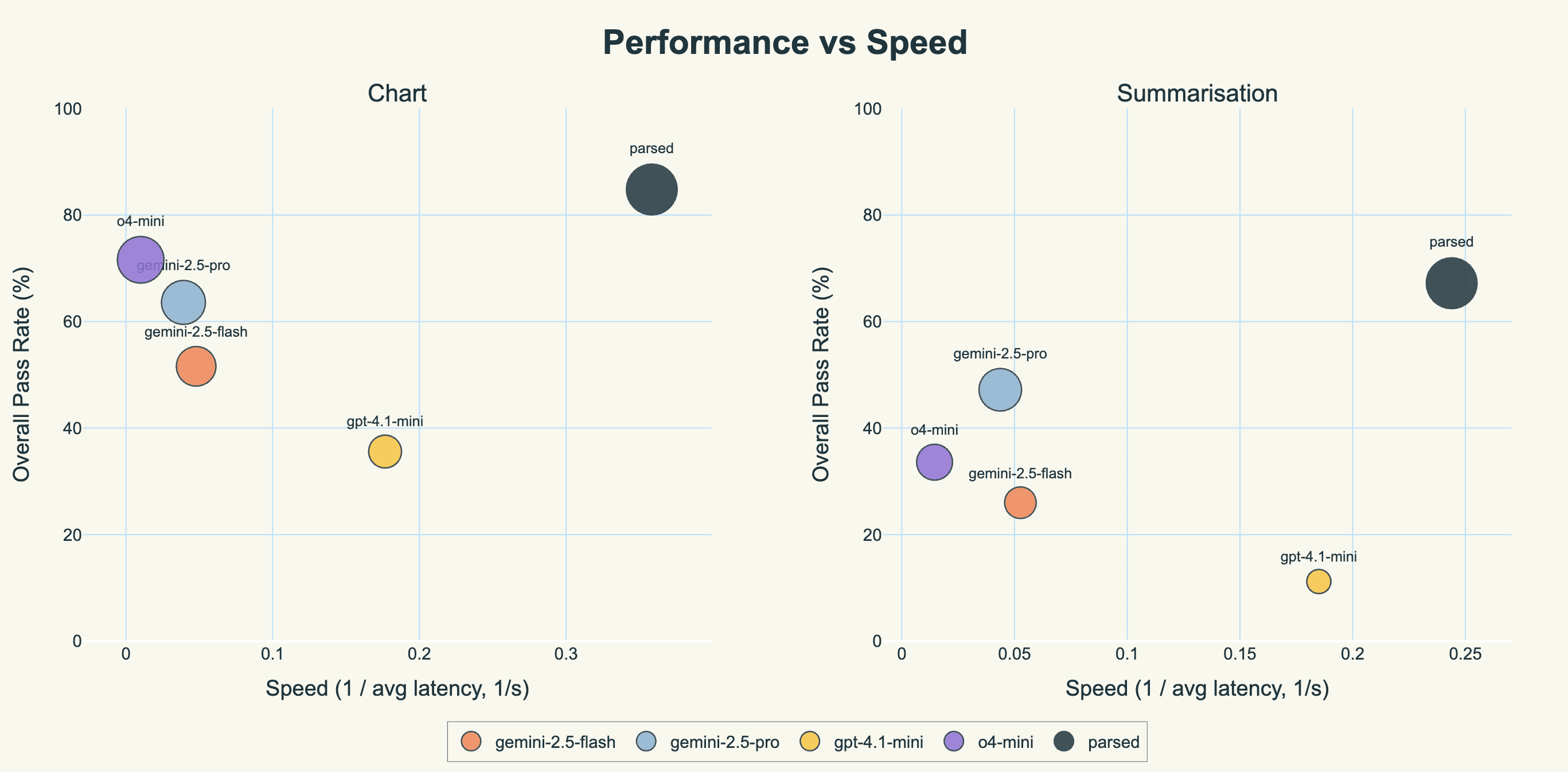
We built a model that achieves 84.8% accuracy on chart generation and 67.2% on summarization, compared to gemini-2.5-pro's 63.6% and 47.2%. It also runs 6-8x faster.
Emergency department notes aren't like other medical documentation. Information comes from multiple sources simultaneously: the patient, EMS, family members, prior records. The clinician must document not just what happened, but what didn't happen, in particular explicitly ruling out dangerous diagnoses.
The system needed to handle:
Complex routing logic where information starts in one section then redistributes to others based on priority
Conditional inclusion rules (include transport mode only if not self-transport, unless configured otherwise)
Template modification that preserves non-contradicted normal findings while adding new observations
High-risk diagnosis detection that matches chief complaints to potential emergencies and tracks rule-out criteria
General-purpose LLMs consistently failed at these tasks. They'd hallucinate provider names, place physical exam findings in the history section, or worse would miss critical diagnoses that hadn't been ruled out.And frontier models fail at emergency documentation
And it’s true, frontier models actually do fail a lot at emergency documentation. They need to maintain multiple concurrent constraints while preserving information semantics, which in some sense is actually quite out of distribution for them. When
gemini-2.5-prosees “regular rate, regular rhythm, no murmurs” and needs to incorporate tachycardia, it faces a constraint satisfaction problem: preserve non-contradicted facts while surgically removing contradicted ones. This requires understanding medical relationships (rate ≠ murmurs) plus precise text manipulation. Most models do one or the other; few do both.
We built comprehensive evaluation frameworks using Lumina for both stages of the pipeline. (You can read more about our LLM-as-judge evaluation construction with Lumina here.) Our client provided 120 micro-checks they used for quality assurance ie specific failure modes they'd identified over months of production use. We semantically partitioned these into our evaluator framework, ensuring complete coverage while organizing them into coherent evaluation dimensions, as well as supplementing them with additional errors and holistic checks we wanted to make for quality.
For the summarization stage (transcript → JSON), we created five evaluators:
Groundedness: No hallucinated information, all facts traceable to source
Semantic categorization: Information placed in correct sections
Conditional logic: Exclusion/inclusion rules correctly applied
Formatting compliance: Age formats, temporal expressions, structural requirements
Clinical quality: Non-redundant, uses proper terminology, applies high-risk diagnosis logic
For the chart generation stage (JSON + template → chart), we created five different evaluators:
Factual grounding: Demographics and findings match exactly
Template modification: Preserves non-contradicted normals, removes contradicted clauses
Structural integrity: Sections included/omitted based on content rules
Information completeness: All required data present, mandatory defaults applied
Formatting and style: Length limits, prefixes, capitalization, data transformations
Each evaluator uses binary pass/fail scoring on specific criteria. A chart passes only if it satisfies all requirements.
We also needed to validate the evaluators themselves. We ran a meta-evaluation process where we generated “perfect” outputs according to our evaluators, and had our customer’s clinical team review these outputs. When they found issues our evaluators missed, we refined the evaluation prompts. When evaluators flagged clinically acceptable outputs, we traced misalignment back to task specifications. We also provided questions about ambiguities surfaced by Lumina for the customer to answer. This iteration continued until our evaluators aligned with expert clinical judgment.
The original system used multiple prompts across different stages - separate prompts for each section of the summarization, another prompt for PE template selection, and more prompts for the chart generation. This created compounding errors and latency.
We consolidated this into two stages:
Stage 1: One prompt handles all 16 sections of summarization
Stage 2: One prompt handles complete chart generation
For PE template selection, we noticed the LLM was essentially pattern-matching against rules. We replaced this with deterministic Python code, eliminating an unnecessary LLM call while improving accuracy to 100%.
This simplification was only possible because we made the first stage robust enough to produce consistent, well-structured outputs that the second stage could reliably process.
We used iterative SFT to train our model, which in this case is qwen3-32b, a dense model (we are also currently in the process of training an MoE model for the same task, qwen3-next-80b-a3b, which speeds up inference significantly at the cost of memory).
Iterative SFT is a simple idea. For each training example, we:
Generate initial output from base model
Run all evaluators to identify failures
Use gemini-2.5-pro to repair the output based on specific failure feedback
Repeat until all evaluators pass
Train on these perfect outputs
This process is more sample-efficient than standard SFT because we're training on outputs that score higher than what even gemini-2.5-pro produces naturally. Each training example provides dense supervisory signal about what went wrong and how to fix it.
We also enhanced our training data through prompt mutation, which is systematically varying the input format while preserving semantic content. This prevented overfitting to specific phrasings.
For the chart generation stage, we added robustness by training on both perfect JSON outputs and unrefined outputs from the summarization stage. This ensures the model handles imperfect inputs gracefully in production.
We include two examples of how iSFT allows us to bake in specific behaviors to the model (that are difficult to prompt for) below.
The most important component is the high-risk diagnosis detector. For each chief complaint, the model must identify dangerous conditions that haven't been ruled out.
For example, subarachnoid hemorrhage is ruled out only if thunderclap headache is absent AND CT within 6 hours is negative. Another example is that pulmonary embolism requires either low-risk Wells score plus negative PERC, or negative imaging.
We trained the model to apply these rule-out criteria exactly. If a dangerous diagnosis isn't explicitly ruled out, it appears in the output with specific next steps: what history to clarify, what exam findings to check, what tests to order.
Physical exam documentation presented a unique challenge. The system starts with standard templates like "Normal Adult" containing default findings. The model must surgically edit these templates based on new findings.
If the template says "regular rate, regular rhythm, no murmurs" and the exam found tachycardia, the model must delete only "regular rate, regular rhythm" while preserving "no murmurs". It then appends "tachycardic" to the remaining text.
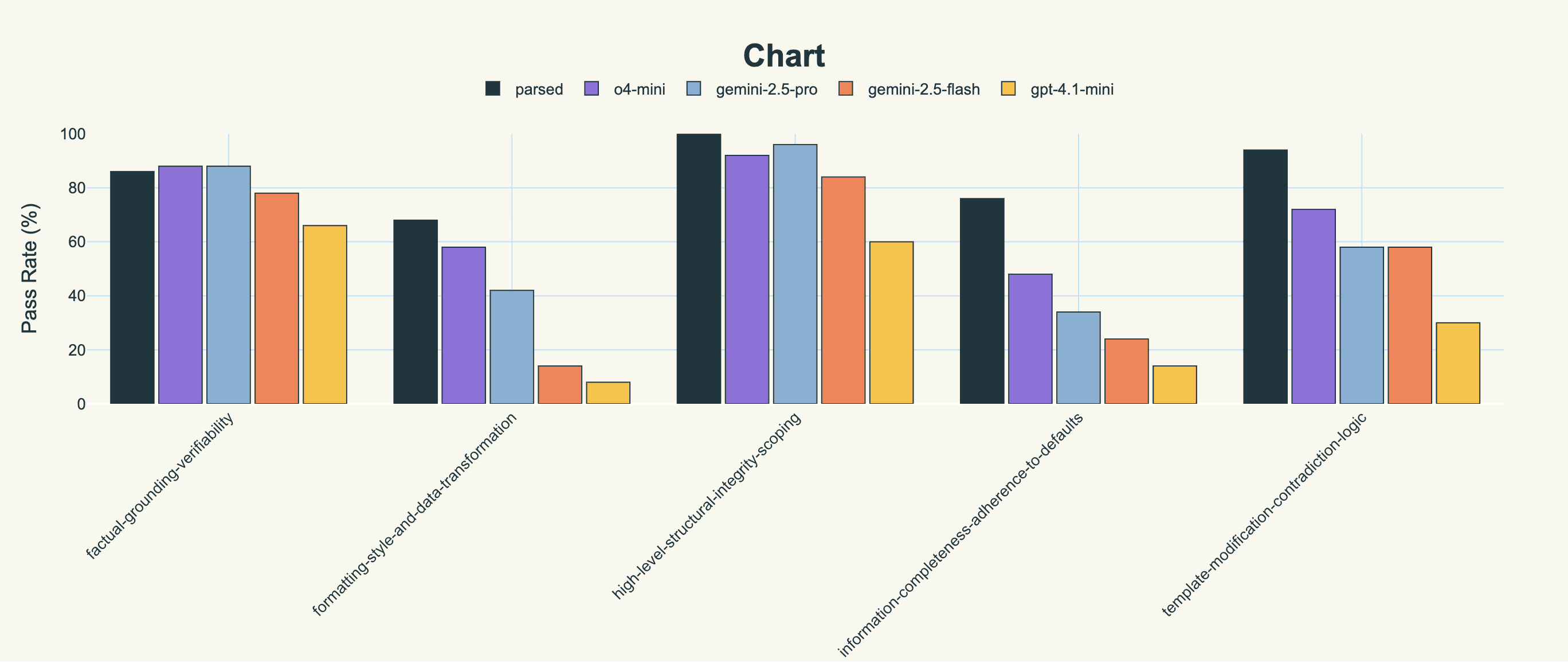
Most models either replace everything or keep everything. Through iSFT with targeted feedback on template modification failures, we taught our model to make precise edits. Our model achieves 94% accuracy on template modification compared to gemini-2.5-pro's 58%.
The headline result is that we outperform gemini-2.5-pro (the SOTA for this task, prior to us training our model) on both summarization and chart generation, by a significant amount. We also do so about 5-7 times faster that gemini-2.5-pro, and just under 25 times faster than o4-mini, which surprisingly was the second best model we tested.
Our model scored 42% better than gemini-2.5-pro on the summarization task (which was the best of the closed-source models). Here, pass rate is defined as the percentage of evaluators that passed (averaged across all types of evaluators and all notes).
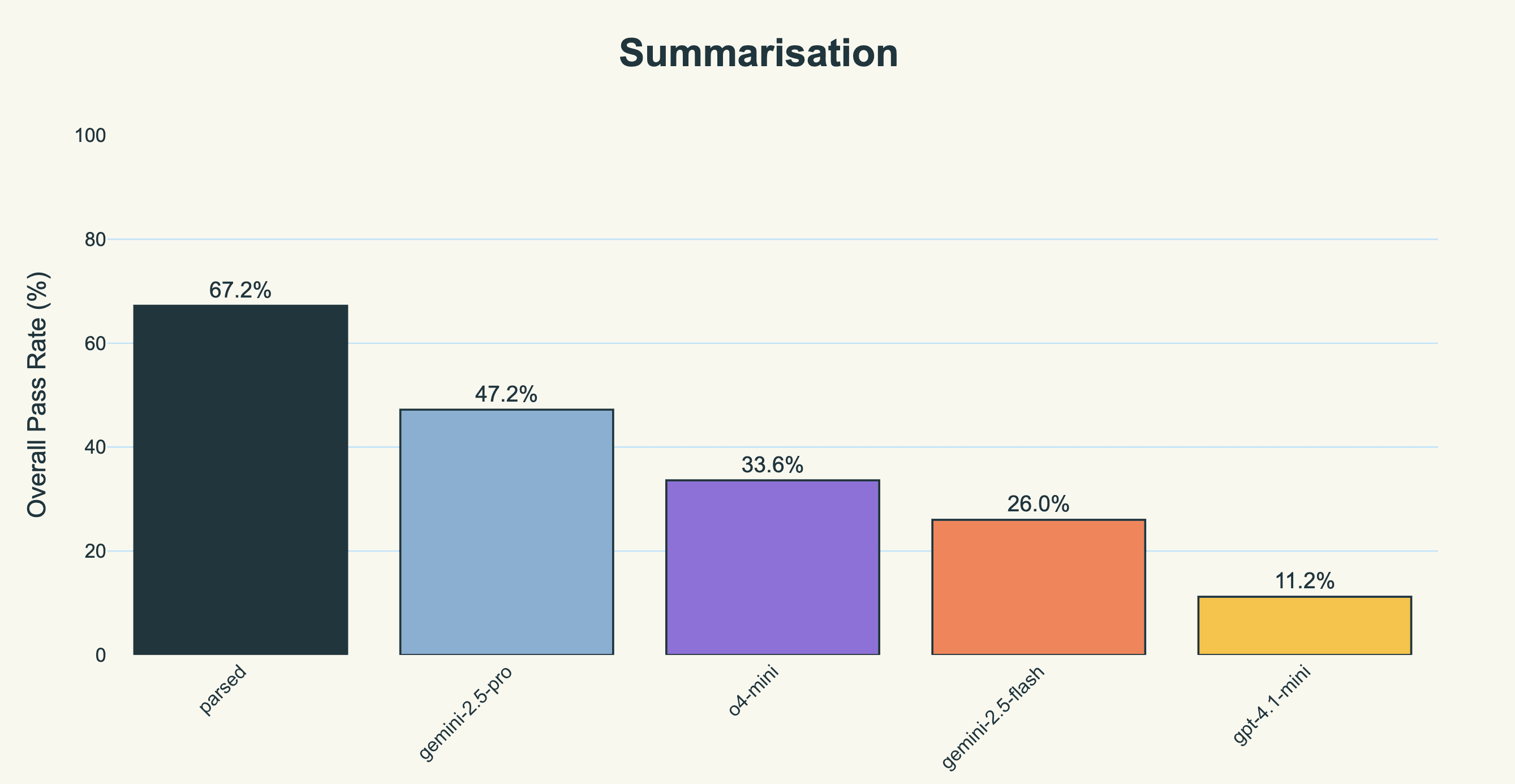
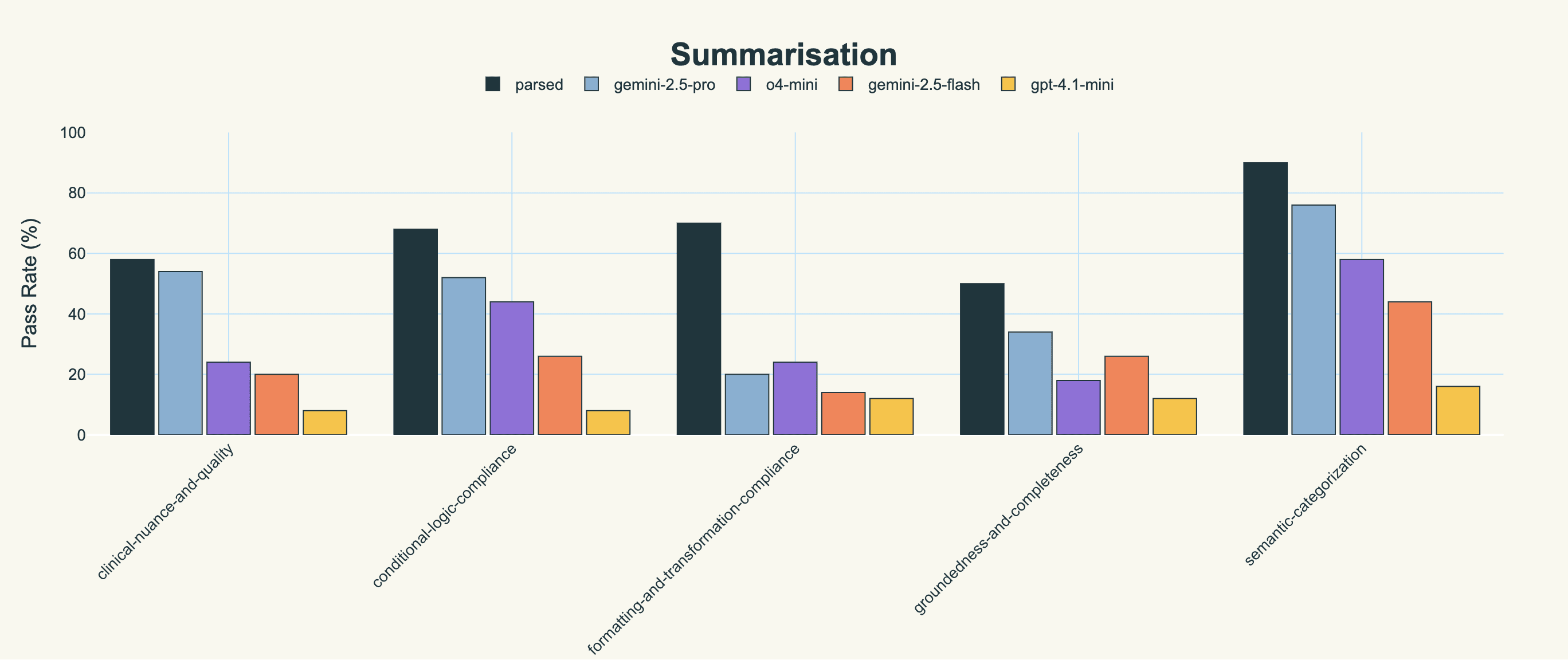
We also include the score on individual evaluators for the sake of completeness.
Similarly, we outperform gemini-2.5-pro by 33% on chart generation, and outperform o4-mini (the next closest model) by 18%.
Importantly, we achieve a score of 100% on structural integrity scoping, and significantly outperform other models in information completeness evaluation.
However, performance is not the only axis a customer must optimize along; another key axis is latency. Thankfully, our model is not only the best, but also the fastest (and by a long way). We use Baseten’s inference stack along with optimized speculative decoding setups to ensure we get blazing inference speeds, minimizing the time the doctor has to wait for a note to be written, which in emergency settings can be very important.
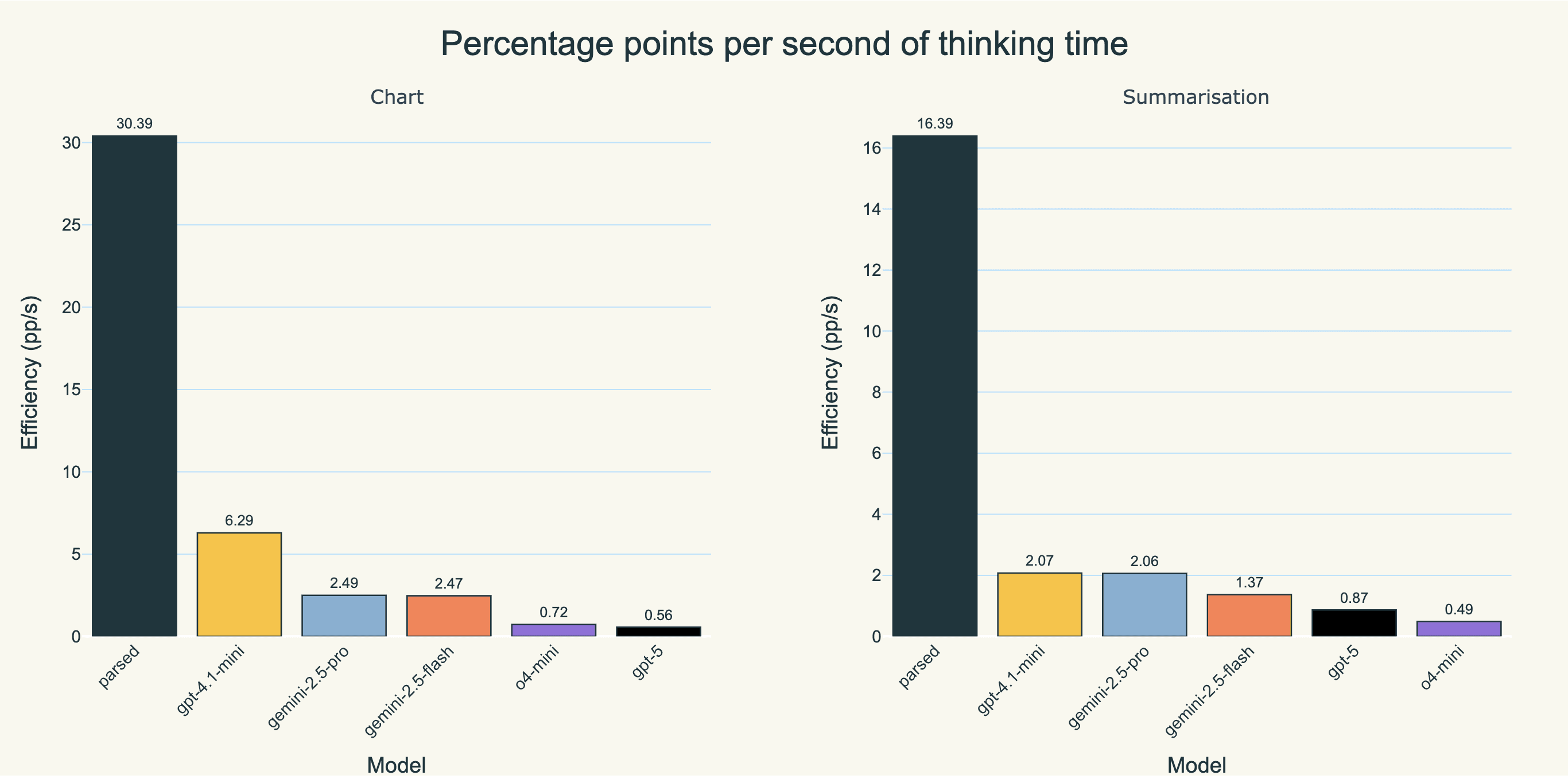
Another nice way to view this is “percentage points achieved per second of thinking time” on the overall aggregated evaluations. Parsed comes out well ahead.
Of course, another thing to note is that the true latency improvement over the previous system was actually much higher, as we the latency improvements come not just from model speed but from pipeline simplification (note though that all models above are using the condensed pipeline for the sake of comparison). By consolidating multiple LLM calls into single stages and replacing pattern-matching tasks with code, we reduced the total number of inference calls from 5+ to 2. We were able to do this because when we can change a model’s weights, we don’t have to break up the task into individual steps in order to be able to prompt for it effectively; we can just teach it the mapping in one step.
Our model currently processes tens of thousands of ED notes weekly across our client’s customer base. This volume is expected to double by year-end as more emergency departments adopt the system.
Example of what our model gets right: One particular case we evaluated stood out to us, where a patient arrives by EMS with chest pain. The transcript mentions the patient has diabetes and takes metformin, but the family member states the patient stopped taking it last month. EMS noted hypotension en route.
gemini-2.5-proactually failed pretty miserably; it placed “stopped metformin” in current medications instead of past medications, included family member as a healthcare provider, put EMS vital signs in the physical exam section, and missed that chest pain requires ACS rule-out documentation. Our model, in contrast, correctly routed discontinued medication to the appropriate section; identified the family as a historian, not a provider; excluded EMS vitals from PE findings while preserving them in HPI, and generated high-risk diagnosis section noting that ACS was not ruled out.
Three factors drove our success:
Comprehensive evaluation before training. We spent weeks with our client's clinical team cataloging every possible failure mode. This upfront investment in evaluation quality set the ceiling for model performance.
Dense feedback through iSFT. Rather than training on whatever gemini-2.5-pro generates, we train on outputs that have been iteratively refined to pass all evaluators. This produces training data of higher quality than any model naturally generates.
Multi-stage robustness. We deliberately trained the chart generation model on both perfect and imperfect JSON inputs from the summarization stage. This ensures graceful handling of upstream errors and eliminates the brittleness of the original multi-prompt pipeline.
Emergency medicine documentation requires precise application of clinical rules while maintaining semantic understanding. By building calibrated evaluators and using iterative refinement to hillclimb these evaluators, we've created a model that outperforms general-purpose systems on both accuracy and speed.
The approach generalizes: build evaluators that capture domain expertise, use iterative refinement to create perfect training examples, then train a specialist model. For regulated industries where errors have consequences, this methodology delivers models that don't just approximate the task under fuzzy prompt instructions but execute it correctly.