Research
October 27, 2025
Robust, sample efficient SFT with prompt mutations
Low-KL divergence prompt mutations: better performance at a fraction of the cost.
Authors
Affiliations
Harry Partridge
Parsed
Charles O'Neill
Parsed
TLDR: Low KL-divergence prompt mutations lead to better performance at a fraction of the cost.
In production use cases, LLMs are often required to perform the same task numerous times. This usually involves using a prompt template - a set of predefined instructions and requirements that are used repeatedly in conjunction with a small set of variable inputs. For example, an LLM might be used to transform documents from one format into another format, adhering to variable instructions specifying the desired structure, length and style.
In this kind of high-volume, repeatable use case, Supervised Fine Tuning (SFT), and Reinforcement Learning (RL) can be employed to optimise a small model to efficiently perform the specific task. However, two interlinked issues often arise:
Prompt brittleness: Since the same set of predefined instructions are present in the input for every example, the fine-tuned model can become brittle and significant performance degradation may be observed based on small changes in these instructions.
Cost:
For vanilla SFT, the amount of data required to achieve a desired performance threshold may be prohibitively expensive to collect.
For RL, producing and grading rollouts can become very expensive, particularly when expensive LLM-as-a-judge rewards are used to grade each individual rollout.
On-policy distillation is more cost efficient than RL since a denser reward signal may be collected from each example, but performing numerous rollouts and grading with a large teacher model is still expensive. In addition, the teacher model must be from the same family (or at least use the same tokeniser) as the student model.
Presupposing that you start with an SFT dataset consisting of inputs and gold standard outputs (constructed either using human labels, distillation from a teacher model, context distillation or iterative refinement), a simple, yet surprisingly effective strategy to address these issues is to:
Isolate the static
prompt templateinstructions that are shared across examplesPerform precise mutations that only alter the phrasing, structure and syntax of the
prompt template, but without affecting the meaning or intent behind the prompt.Re-insert the variable components of the task into these mutated instructions and combine with the same gold standard outputs.
This process multiplies the size of the dataset by several fold without having to re-collect any more gold standard outputs. It also ensures that the model does not over-index on the idiosyncratic specifics of the initial prompt template. Indeed, repeatedly using the same prompt template means that the training process exposes only a particular surface of the weight manifold. By exposing the model to different variations of the same latent intent, the model is forced to generalise and extrapolates better to unseen inputs.
Robustness
In practice, when someone writes down the desired behaviour of their model into a prompt template, they are searching for a conditional context $\mathcal{C}$ in which the model will respond appropriately to the variable inputs $\mathcal{V}_i$; they care about the specific details of their prompt only insofar as that prompt induces the desired behaviour. However, if the optimal policy is going to be trained into the model by using gold standard outputs $\mathcal{Y}_i \sim \pi_{\text{opt}}(\mathcal{V_i})$, then why is it even necessary to precondition with $\mathcal{C}$ at all? Why not simply train on pairs $(\mathcal{Y}_i, \mathcal{V}_i)$? The issue with this approach is that it is severely off-policy: the base model is extremely unlikely to produce $\mathcal{Y}_i$ from $\mathcal{V}_i$ without the context $\mathcal{C}$.
It has been demonstrated that KL divergence between a model’s policy distribution and the training dataset is the key predictor of catastrophic forgetting. Since the KL divergence of the base model with the raw input-output dataset $(\mathcal{Y}_i, \mathcal{V}_i)$ is extremely high, this will result in a model that performs very poorly when shifted even slightly out of distribution. This is why it is necessary to train on the combined $(\mathcal{V}_i, \mathcal{C})$ dataset, even though the desired behaviour is embedded in the outputs themselves.
However, we can do even better than just $(\mathcal{V}_i, \mathcal{C})$. In fact, any $\mathcal{C}'$ which induces a low KL divergence between $\pi_\text{base}(\mathcal{V}_i, \mathcal{C}')$ and $\pi_\text{opt}(\mathcal{V}_i)$ will result in a robust trained model. We can measure this KL divergence on a given candidate prompt mutation, and select only the lowest divergence mutations. This is something we’re actively looking into.
Prompt Mutations in Practice
Parsed uses iterative refinement to construct optimal outputs for a given input example. This process leverages a significant amount of computation in running evaluations and refinements, and may therefore cost thousands of dollars for a large dataset. For only a handful of dollars, prompt mutations can be used to double or triple the size of this dataset with no performance reduction, saving thousands of dollars relative to further refinement.
Furthermore, for customers with limited data, prompt mutations provide us an easy method with which to increase the size of the training dataset, resulting in much stronger performance than would have otherwise been possible.
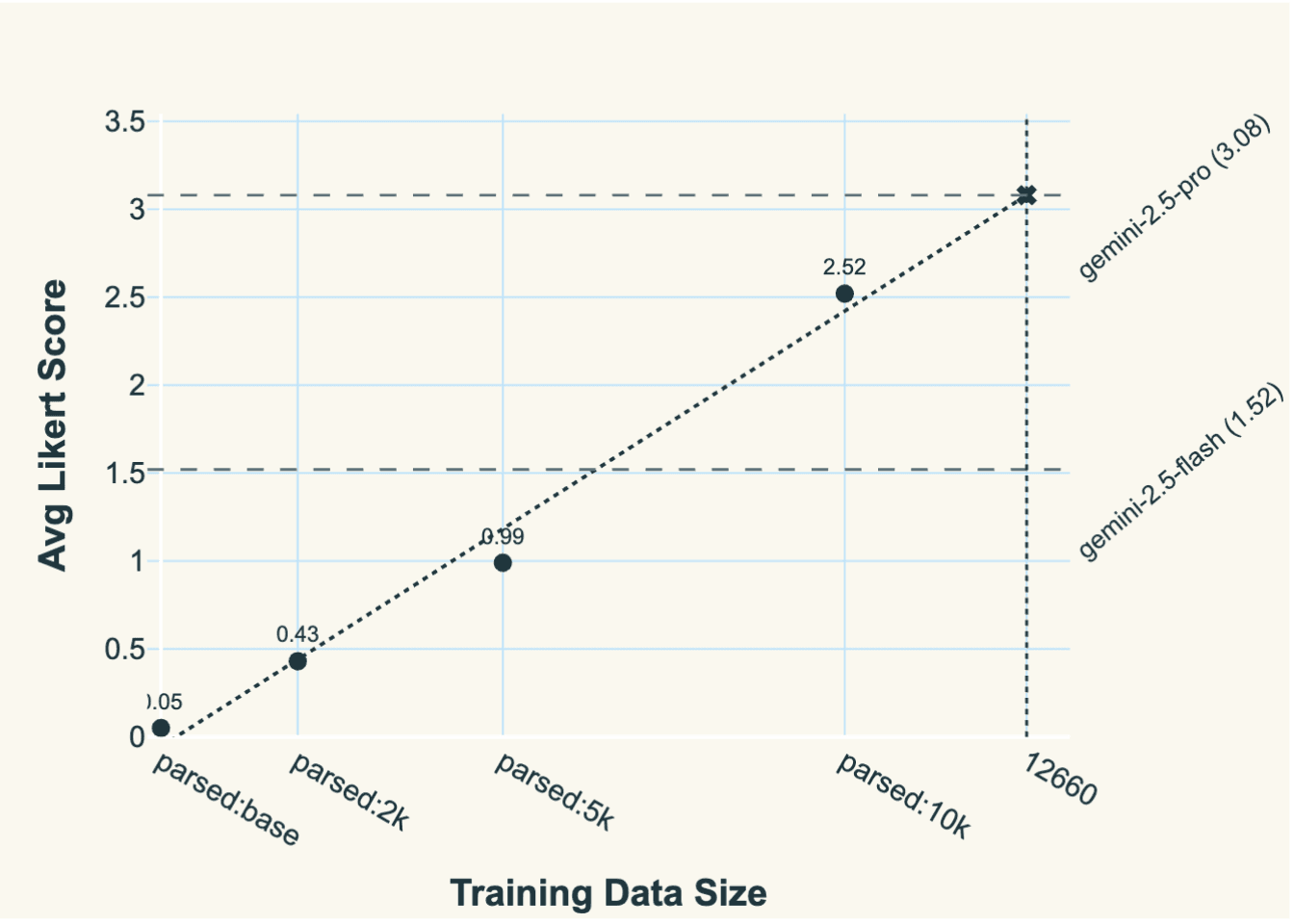
This customer started with a limited sample set of 5000 samples in their dataset. Performing only a single prompt mutation allowed us to double the size of the dataset to 10k datapoints and resulted in above-trend performance virtually for free. All models trained for 2 epochs from a Gemma-3-27B-it baseline. The Likert score represents the sum of scores from an ensemble of binary PASS/FAIL LLM-as-a-Judge evaluators.
On Policy Prompt Mutations
Prompt mutations can also be used in conjunction with on-policy training strategies such as on-policy distillation or RL. In this setting, it is no longer necessary to select low KL-divergence mutations, since the outputs are generated online. Instead, prompt mutations provide a simple way to broaden the training task and ensure that trained models are less fragile to small changes in the input task. Again, this is something we’re experimenting with.
Future work
Instead of merely sampling for low KL divergence prompts, it is possible to directly optimise a KV cache $\mathcal{C}'$ that minimises the KL divergence of $\pi_\text{base}(\mathcal{V}_i,\mathcal{C}')$ with $\pi_\text{opt}(\mathcal{V}_i)$. We hypothesise that training with such a context will result in even more robustly trained models.
We are also interested in exploring the scaling laws of prompt mutations; we would like to have a better characterisation of the marginal benefit of the nth prompt mutation.