Case study
August 15, 2025
Fine-tuning small open-source LLMs to outperform large closed-source models by 60% on specialized tasks
27B open-source model outperforms biggest OpenAI/Anthropic/Google models on real healthcare task.
Authors
Affiliations
Charles O'Neill
Parsed
Mudith Jayasekara
Parsed
Max Kirkby
Parsed
TL;DR: How small open-source models — when paired with rigorous evaluation and task-specific optimization — can outperform the largest proprietary reasoning models on complex real-world tasks like healthcare scribing. This approach delivers 60% better accuracy, 50-80% lower inference cost, and 2-3x faster latency and greater transparency and reliability.
Introduction
The conventional wisdom that open-source LLMs represent a fundamental performance-capability tradeoff stems from outdated assumptions. Early LLM comparisons showed proprietary models dramatically outperforming open alternatives. However, Chinchilla scaling laws revealed that compute-optimal training requires balanced parameter-to-token ratios rather than pure parameter scaling, demonstrating diminishing returns beyond 70B parameters for most tasks. Further, when the distribution of the task we require a model to generate for is sufficiently constrained, a much smaller model optimized specifically for that distribution can outperform bigger models many times its size.
The research team at Parsed builds programmatic, domain-aligned evaluation systems that decompose tasks into granular checks, reflect expert judgment, and integrate directly into model training and deployment pipelines. Parsed’s evaluation-first methodology — designing and implementing an evaluation framework before developing the model or adaptation strategy — can save 50-80% in inference costs compared to the big labs while providing higher quality outputs for the customer. For some of their customers this represents a saving of millions of dollars a year. The Parsed platform uses this evaluation system to drive continual reinforcement learning, something only possible with open weight models due to full parameter access and algorithmic flexibility. Parsed’s team also uses mechanistic interpretability techniques to attribute every output token back to the input token, providing first-principles explanations of model behavior. This makes Parsed’s models not just cheaper and higher-performing, but also transparent, auditable, and self-improving over time.
Open Models and Task-Specific Inference
Task-specific fine-tuning exploits the fundamental principle that specialized models require lower entropy output distributions than general-purpose models. When a 27B parameter model is fine-tuned for a specific task, it can dedicate its full representational capacity to a narrower probability space, effectively increasing its bits-per-parameter efficiency by 2-3 orders of magnitude compared to general inference. This specialization enables aggressive optimization strategies unavailable to general models, such as domain-specific vocabulary optimization. The compound effect is dramatic. As an example, Parsed’s fine-tuned a Gemma 3 27B model to achieve 60% better performance than Claude Sonnet 4. Parsed’s experience suggests this performance isn't anomalous; medical, legal and scientific domain-specific fine-tuning consistently shows 40-100% improvements over base models.
The technical prerequisites for successfully challenging the open source performance tradeoff center on three critical factors: high-quality task-specific data curation, rigorous evaluation frameworks, and iterative optimization cycles. Successful fine-tuning requires tens of thousands of high-quality examples with consistent formatting and comprehensive coverage of the task distribution.
Parsed Healthcare Use Case: Scribe
One type of customer that Parsed has worked closely with in the healthcare space are ambient scribes, who transcribe clinician-patient interactions and write clinical notes in the style of that doctor for the particular interaction. Whilst on the surface this may seem like a simple and innocuous summarisation problem, there are several aspects that make it challenging even for the largest frontier models.
First, transcriptions can be as long as a couple of hours, meaning the language model must process upwards of 30,000 tokens of transcript (not including the prompt and other information), which leads to degraded quality, increased hallucinations, and lower adherence to instruction following. Second, it is difficult to describe precisely the many levels of nested instructions and requirements that define the contours of this task; for instance, it is hard to set a threshold for exactly how much information is relevant, particularly when the doctor has the option to choose different levels of detail. Finally, the transcript itself often contains errors (due to noisy doctor rooms, complex medical terminology not handled well by the speech-to-text model, etc.) and thus the LLM generating the clinical note must be able to infer misspellings, mis-quotes, incorrect language all without making unreasonable leaps about what was said.
Fortunately, with the right optimization setup, all of these issues can be solved. Parsed has worked with several scribes now. By defining a rigorous evaluation harness that agrees with an expert human evaluation of a clinical note, they can both construct the most optimized SFT pipeline and use the evaluation harness itself as a reward model for RL. Both of these allow Parsed to surpass the performance of the largest frontier reasoning models with significantly reduced cost.
Parsed's Advanced Evaluation Methodology
Healthcare applications demand the development of highly sophisticated evaluation frameworks that go far beyond standard assessment approaches. Clinical documentation requires evaluation across multiple complex, orthogonal dimensions: clinical soundness and safety, source fidelity to the transcript, coverage and salience of what matters for the encounter, and strict conformance to the clinician's template and style. A note can be clinically sound while missing important patient complaints, or it can capture every detail while ignoring the provider's formatting and voice.
The complexity of these requirements necessitates building advanced, multi-layered evaluation harnesses that can reliably assess each dimension with clinical precision. Parsed has invested heavily in developing these sophisticated evaluation methodologies; they’ve created the frameworks for ensuring clinical-grade model performance.
The solution lies in constructing an evaluation harness that aligns with the judgment of clinical experts: in this case, the doctors building and using the scribe products themselves. First, Parsed’s forward-deployed team works closely with the subject matter experts within the company to meticulously define error modes and establish precise decision points the expert would use to judge whether that error mode was present or not. This process requires extensive data analysis and iterative refinement on Parsed’s side to build evaluation harnesses that truly reflect the complexity of clinical understanding.
This then allows Parsed to decompose the evaluation task into granular, objective, deterministic, binary checks. Parsed builds a rubric fan-out where specialized models verify individual aspects the domain expert has defined: one might validate that subjective patient complaints are preserved verbatim, another might ensure differential diagnoses follow the clinician’s reasoning pattern. These binary checks aggregate into higher-level metrics — Clinical Soundness & Safety, Source Fidelity, Coverage & Salience, and Template & Style Fidelity — which combine into a single harness score. This allows Parsed to reduce intra- and inter-evaluator variance by confining each LLM call to a very specific eval check (also allowing them to use smaller models and parallelise). By shadowing expert physicians who review notes and codifying their decision-making process, the evaluation harness becomes the ground truth that enables rapid iteration.
Parsed then uses this evaluation harness to benchmark existing models, but more importantly as the foundation for SFT and RL optimization. For RL, the eval harness itself is used as the reward signal during training, something only possible when you have reduced the noise and inconsistency through the construction of a rigorous evaluation system, rather than a single evaluation prompt.
Final Results
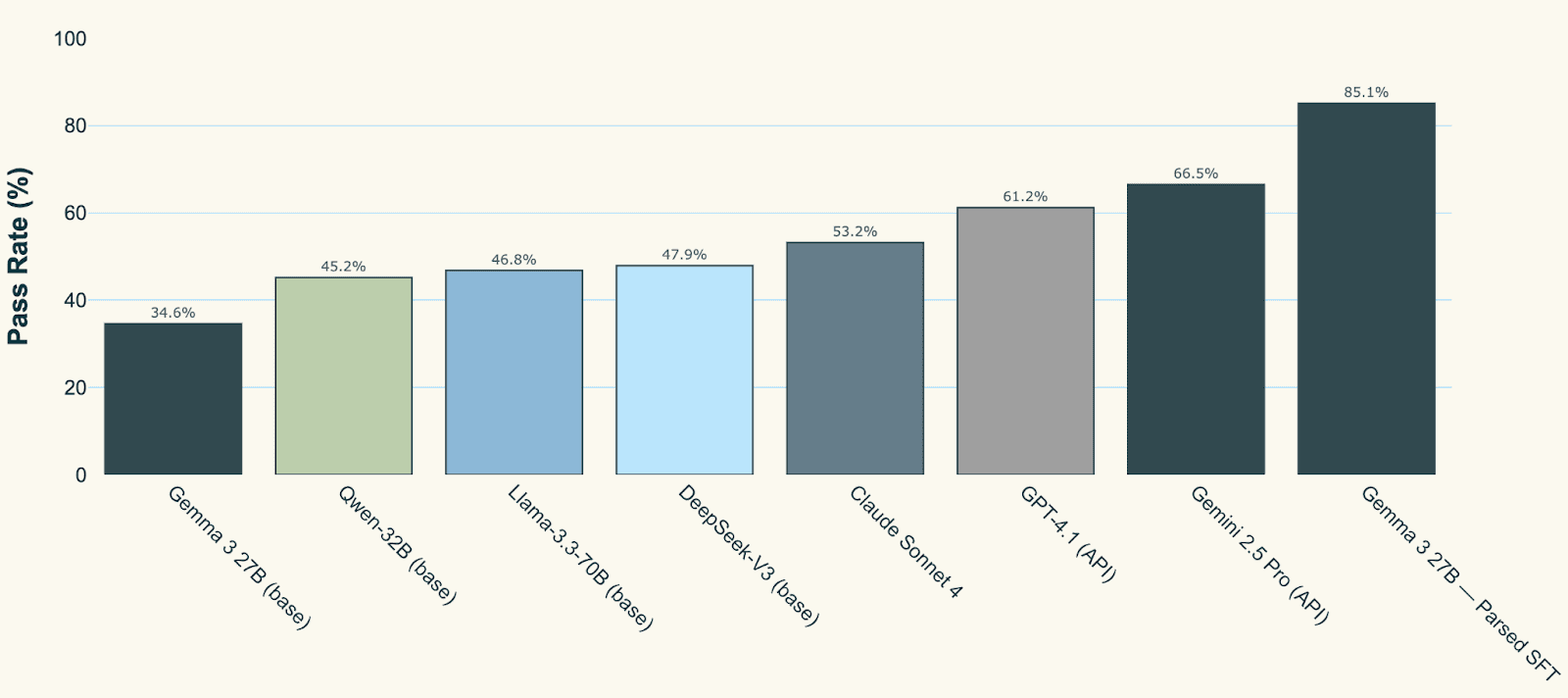
Parsed first focuses on SFT in order to bring the open-source model above the performance of thinking models like gemini-2.5-pro and o3. Whilst they then do continual RL to compound this improvement over time as more data comes in, the SFT step alone warrants customers swapping out big generalist models for the much smaller model optimized specifically for their task. Here, as an example, Parsed fine-tunes Gemma 3 27B (the worst-performing of the models initially tested).
Before Fine-Tuning: For the clinical scribe task, Parsed set the baseline as the performance of Sonnet 4 (a model commonly used by clinical scribe companies) and benchmarked Gemma 3 27B against it. Unsurprisingly, Gemma (a much smaller model) performed 35% worse on the evaluation harness. Strong open baselines sit a clear step below Sonnet 4: Qwen-32B by roughly 15% lower, Llama-3.3-70B around 12% lower, and DeepSeek-V3 about 10% lower. Among proprietary generalists, GPT-4.1 lands about 15% better than Sonnet 4, with Gemini-2.5-Pro closer to 25%.
After Fine-Tuning: However, after fine-tuning Gemma 3 27B on tens of thousands of harness-optimized examples, the results were transformative: the fine-tuned model outperformed Claude Sonnet 4 by 60%. Not only is it better, but being a much smaller model it is significantly faster and cheaper.
Parsed can then serve this smaller, fine-tuned model specifically for the customer with much greater reliability than can be provided by the big labs.
In addition to cost and accuracy gains, a task-optimized 27B model delivers materially lower latency than frontier models like Claude Sonnet 4. With far lower per-token compute and no general-purpose reasoning overhead, the 27B model achieves significantly faster time-to-first-token and 2-3x faster end-to-end generation times.