Research
May 8, 2025
Do transformers notice their own mistakes? Finding a linear hallucination detector inside LLMs
A linear signal in LLMs reveals hallucinations, is detected by a frozen observer, and steered with a single vector.
Authors
Affiliations
Charles O'Neill
Parsed
Sviatoslav Chalnev
Independent
Max Kirkby
Parsed
Rune Chi Zhao
Australian National University
Mudith Jayasekara
Parsed
Large language models can write beautiful prose, translate languages, and even generate code. But they also have a curious tendency to "hallucinate" – to confidently state things that are plausible-sounding but completely unsupported by the context they were given, or even factually incorrect. This is a major roadblock for deploying them in sensitive applications. When a model quietly slips in a statement its own context can't back up, does it, in some sense, realise it's gone off-script? And could another AI, acting as a careful observer, pick up on this?
In our new paper, we explore how a separate "observer" model can detect such contextual hallucinations. This observer reads the entire text (initial context + continuation) and, in a single pass, determines if the continuation is unsupported. A simple, linear signal within the observer's activations robustly flags these unsupported statements. We evaluate on ~1 000 examples each from XSum and CNN/Daily Mail, and we introduce ContraTales: 2000 miniature stories that end in a deliberate logical contradiction.
The Observer's Eye: A New Way to Spot Hallucinations
Think of a human proof‑reader: read the whole document, then ask, “Does the ending follow?” Our "observer paradigm" is analogous. We take a standard transformer (like Gemma-2), ensure it didn't participate in creating the text, and feed it the full document. We then ask: based on its internal state, does it consider the last part a hallucination?
This setup is generator-agnostic (no need for the original model’s internals) and works in a single forward pass, making it efficient.
A Linear Clue to Hallucinations
We hypothesised that an observer model's internal representation of a hallucination might be linear. We tested this by training a linear probe (logistic regression) on the observer's residual stream activations, taken at the end of the potentially hallucinated sentence.

Figure 1: Layer sweep. A single linear probe (logistic regression) achieves > 0.95 F₁ across layers 12‑30 on news data and > 0.70 on logical contradictions.
Figure 1 shows these linear probes perform well, achieving high F₁ scores (up to 0.99 on news benchmarks). The ability isn't confined to just one "magic" layer; it’s a persistent representation in the model’s residual stream. Performance rises sharply in early layers, then forms a broad plateau in middle-to-late layers, suggesting the representation of "contextual support" is built up and stably present.
Outperforming Heuristics, Especially on Tricky Logic
How does this linear probe compare to other detection methods? We benchmarked it against lexical overlap, entity verification, semantic similarity, and attention-pattern analysis (e.g., Lookback Lens).¹
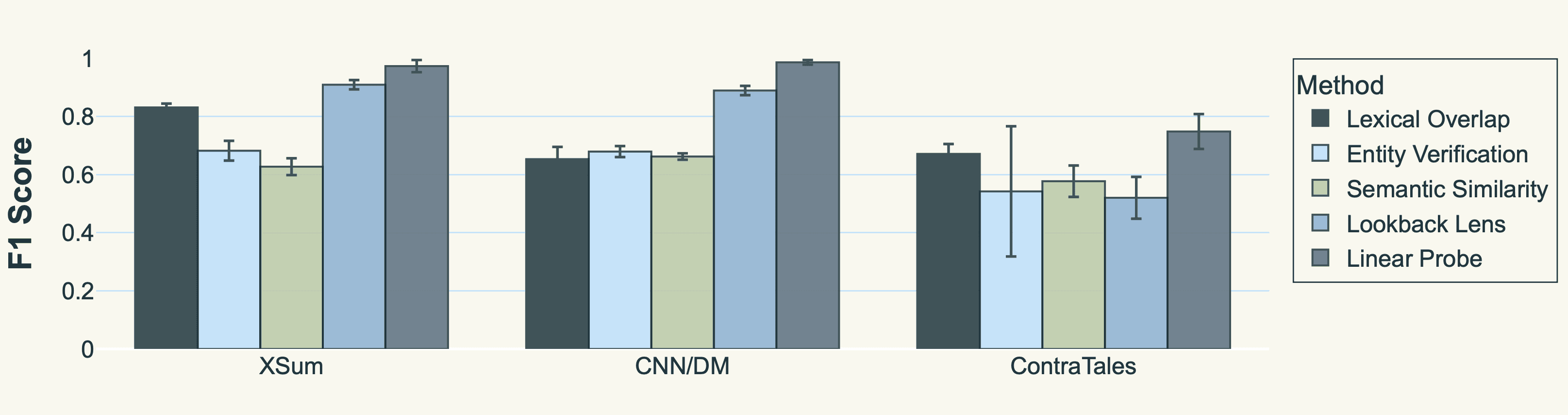
Figure 2: Baseline comparison. The residual‑stream probe outperforms overlap, entity, similarity, and attention heuristics by 5–27 F₁ points.
Our linear probe (Figure 2, right-most bar in each group) outperforms these baselines by 5–27 F₁ points. The difference is stark on ContraTales, where contradictions are purely logical (e.g., "Jack is bald… Jack went to get a haircut."). Surface-level cues falter here, but the linear probe maintains strong performance (0.84 F₁ with our largest observer).
A Consistent & Transferable "Hallucination Axis"
This "hallucination-detecting direction" is not a quirk.
Across Model Sizes: The layer-sweep pattern (Figure 1) is consistent across Gemma-2 models (2B to 9B parameters).
Across Datasets: A linear probe trained on one news corpus transfers well to another with minimal performance drop.
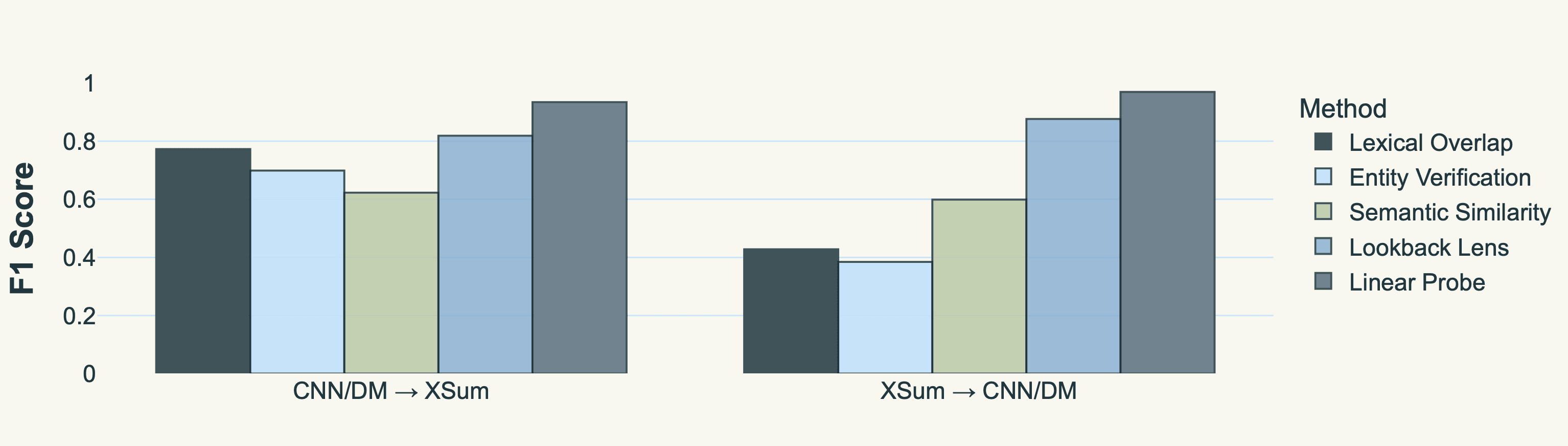
Figure 3: Cross‑domain transfer. Probes trained on one news corpus retain > 0.90 F₁ when evaluated on another, while surface heuristics halve in accuracy.
Figure 3 shows this transferability. While lexical cues degrade when styles change (e.g., Train XSum → Test CNN/DM), the linear probe remains robust, suggesting it captures a fundamental representation of contextual consistency.
What Part of the Observer's "Brain" Tracks Hallucinations?
If a linear direction signifies hallucinations, which transformer components represent it? We used gradient-times-activation attribution to trace the probe's decision. The signal isn't diffuse nor primarily in attention heads. Instead, a sparse, consistent cluster of MLP (feed-forward) blocks in late-middle layers appears key.
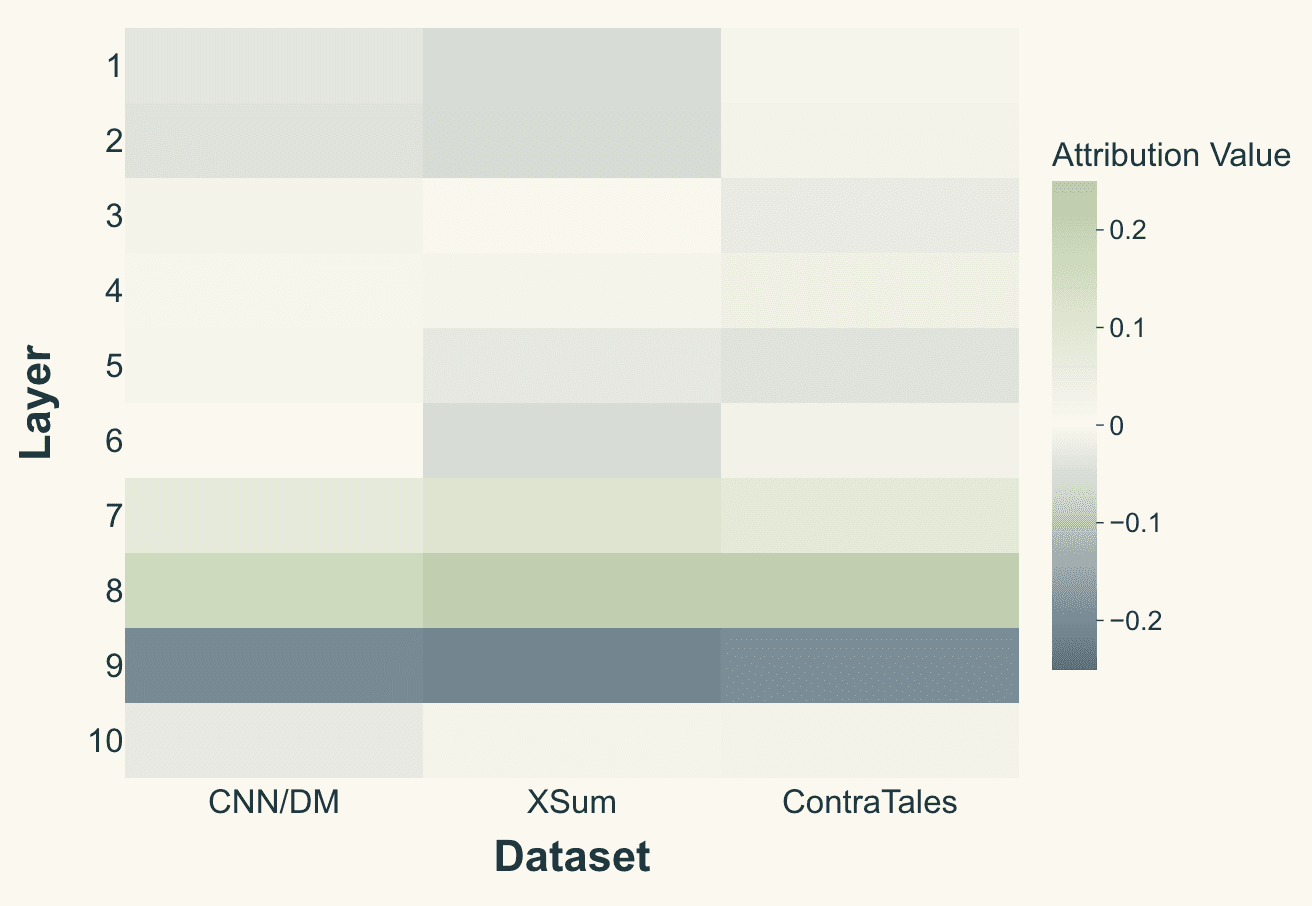
Figure 4: MLP attributions. Only layers 7–9 make systematic contributions to the hallucination logit (legend range e.g., −0.3 … +0.3); heads show no consistent pattern.
Figure 4 shows that for a probe on layer 10 of Gemma-2-9B, MLP blocks in layers 7 and 8 consistently push the representation towards "hallucination" (positive attribution), while layer 9 pushes away (negative attribution). This {positive → strong-positive → negative} MLP triplet recurs across all tested datasets, indicating a compact, responsible sub-circuit.
Is This Representation Causal? Can We Steer a Generator?
To test causality, we injected the normalised ‘hallucination vector’ into a generator’s residual stream while it wrote summaries (known as steering).

Figure 5: Causal steering. Scaling the hallucination axis modulates hallucination (black) and repetition (green) rates in opposite directions. (Figure ideally shows two y-axes and 95% CI bands)
Figure 5 shows a monotonic trade-off: steering with α=+60 increases the hallucination rate to 0.86, while α=−60 results in a 0.35 rate (a 51 percentage point swing across this range). This demonstrates that the linearly decodable direction is an actionable control knob.
Sharpening the Signal: Finetuning Helps
Can an observer's detection be improved without new hallucination labels? We lightly finetuned observer models on only correct (non-hallucinated) text from the ContraTales domain.² This involved two epochs of SFT (AdamW, LR 1×10−5, context 512, batch 64).
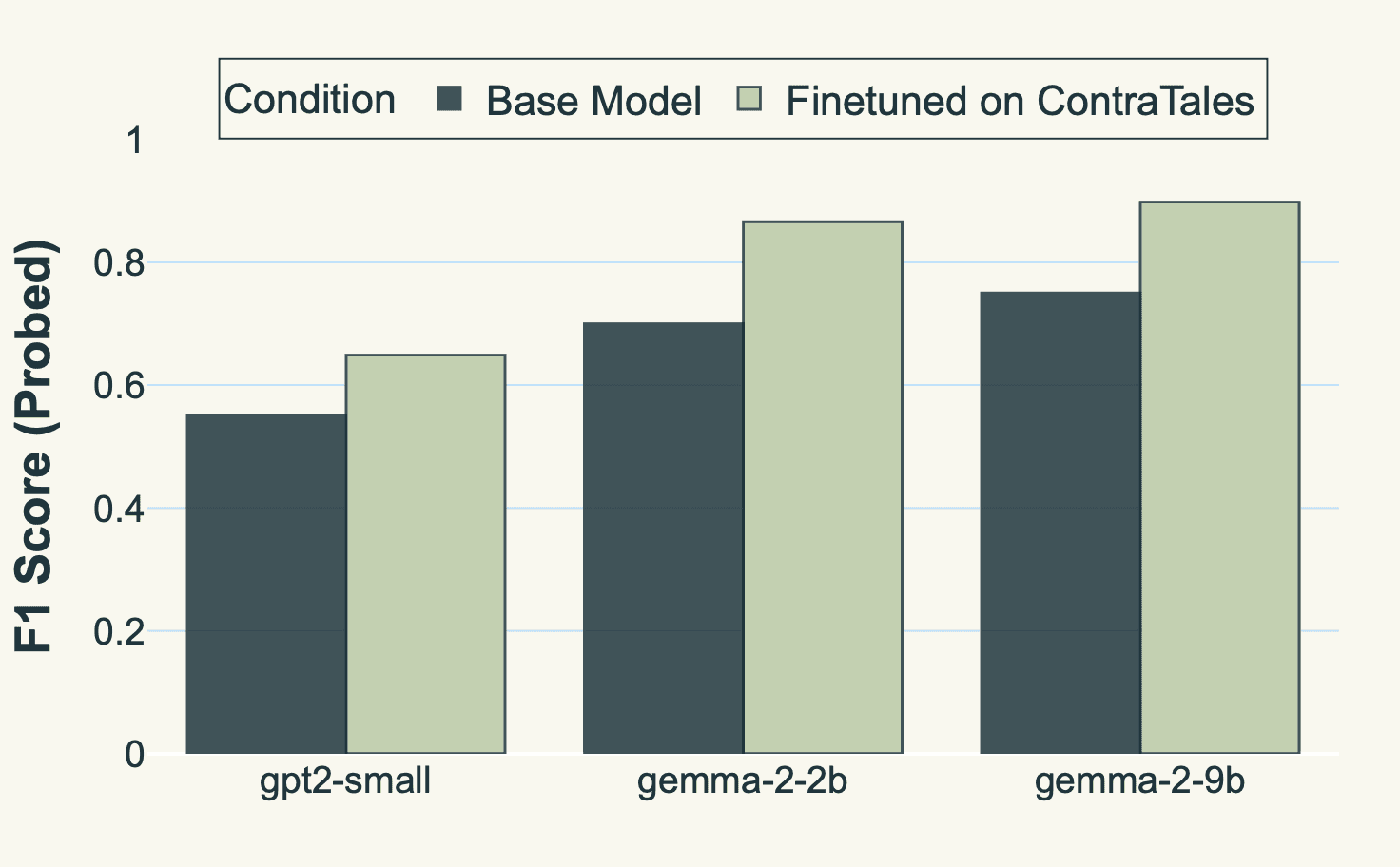
Figure 6: Domain Adaptation. Two‑epoch SFT on 1k correct ContraTales examples lifts probe F₁ by 0.10–0.17.]
Figure 6 shows this unsupervised domain adaptation improved the linear probe's F₁ score upon retraining. For Gemma-2-9B on ContraTales, F₁ jumped from 0.75 to 0.89. Exposure to coherent text sharpens the model's internal representation of supported statements. Most experiments fit on a single 48 GB H100 GPU; finetuning used 8xH200 GPUs (wall-clock time typically under an hour), and steering experiments also benefited from multiple GPUs for latency.
Why This Matters
Generator-Agnostic Detection: Our work demonstrates a simple, single-pass method to detect contextual hallucinations without needing access to the generating model's internals.
Linearity of Complex Concepts: It shows that a complex property like "contextual support" can be robustly represented along a single linear direction in activation space.
Causal Control: The identified direction is not just correlational but can be used to causally influence a generator's tendency to hallucinate.
Limitations & Future Work
Our probe handles single‑span contradictions; multi‑hop reasoning and world‑knowledge gaps remain unsolved.
Persistent Challenges: Some subtle logical contradictions still evade this linear probe.
Scope: Current work focuses on single-sentence contradictions; multi-span or more distributed hallucinations are an area for future research.
Circuit Detail: What computations are these specific MLP layers performing?
Non-linear Components: How do non-linear aspects of the model's representation contribute to understanding consistency?
To help accelerate research, we release the 2,000-example ContraTales benchmark.
Footnotes
¹ For example, Lookback Lens (Chuang, 2024). See paper for full citations of baseline methods.
² In the domain adaptation experiments, the observer model itself is finetuned, departing from the "frozen observer" premise of other sections. The linear probe is then retrained on this modified observer.