Research
November 11, 2025
BYO SWE-grep: automatically train blazing fast search sub-agents on your knowledge base (Pt. 1)
RL-trained search subagents that learn your knowledge base’s structure for fast, reliable retrieval
Authors
Affiliations
Charles O'Neill
Parsed
Jonathon Liu
Parsed
Recently, Windsurf announced they had trained quasi-foundation models that acted as subagents able to very quickly search for relevant parts of code (the overall aim was assisting the big coding model which called these subagents to do search). We have previously RLd a lot of models to do search in contexts outside of coding, i.e. when customers want a model capable of searching a knowledge base in a much more flexible way than static RAG, with a higher ceiling, a model that actually intimately understands their knowledge base. Here, we announce our own Search Subagents training product, available to current Parsed customers and shortly available in our platform.
Although our Search Subagents tool also contains the ability to also directly RL the model on an evaluator set (a collection of LLM-as-judge prompts, often optimised through Lumina), we focus in this post on the search ability. We often recommend using non-RL methods like iSFT and RGT to train the model to do the final composition of the answer after the search, rather than RL, as this becomes too low bandwidth.
Why Knowledge Base Search is Different
Knowledge bases in regulated industries are a nightmare for traditional search. You've got thousands of insurance policies, clinical guidelines, and regulatory documents, all interconnected in ways that only domain experts understand. RAG fails here because it retrieves based on superficial similarity rather than actual understanding. It'll match keywords but miss the important cross-reference three documents away that actually answers the question. And in healthcare or insurance, getting this wrong isn't not only unhelpful but potentially catastrophic from a liability perspective.
While Windsurf solved this for code with SWE-grep, enterprise knowledge bases are fundamentally different beasts. Each customer's knowledge base has its own unique structure, terminology, and web of interconnections that have evolved over years. The key insight we had is that you need a model that actually understands this specific knowledge base, not just a general-purpose searcher. And importantly, you probably don’t need a massive model to achieve this, so we can make it run fast.
TF-IDF: The Underrated Middle Path
We spent months experimenting with different search primitives and landed on something surprising: TF-IDF is actually optimal for this task. On one end of the spectrum you have exact match tools like grep, which are fast but inflexible. On the other end you have semantic embeddings, which are flexible but opaque and often wrong in subtle ways. TF-IDF sits right in the middle, handling synonyms and partial matches while remaining interpretable enough that customers can understand why certain documents were retrieved.
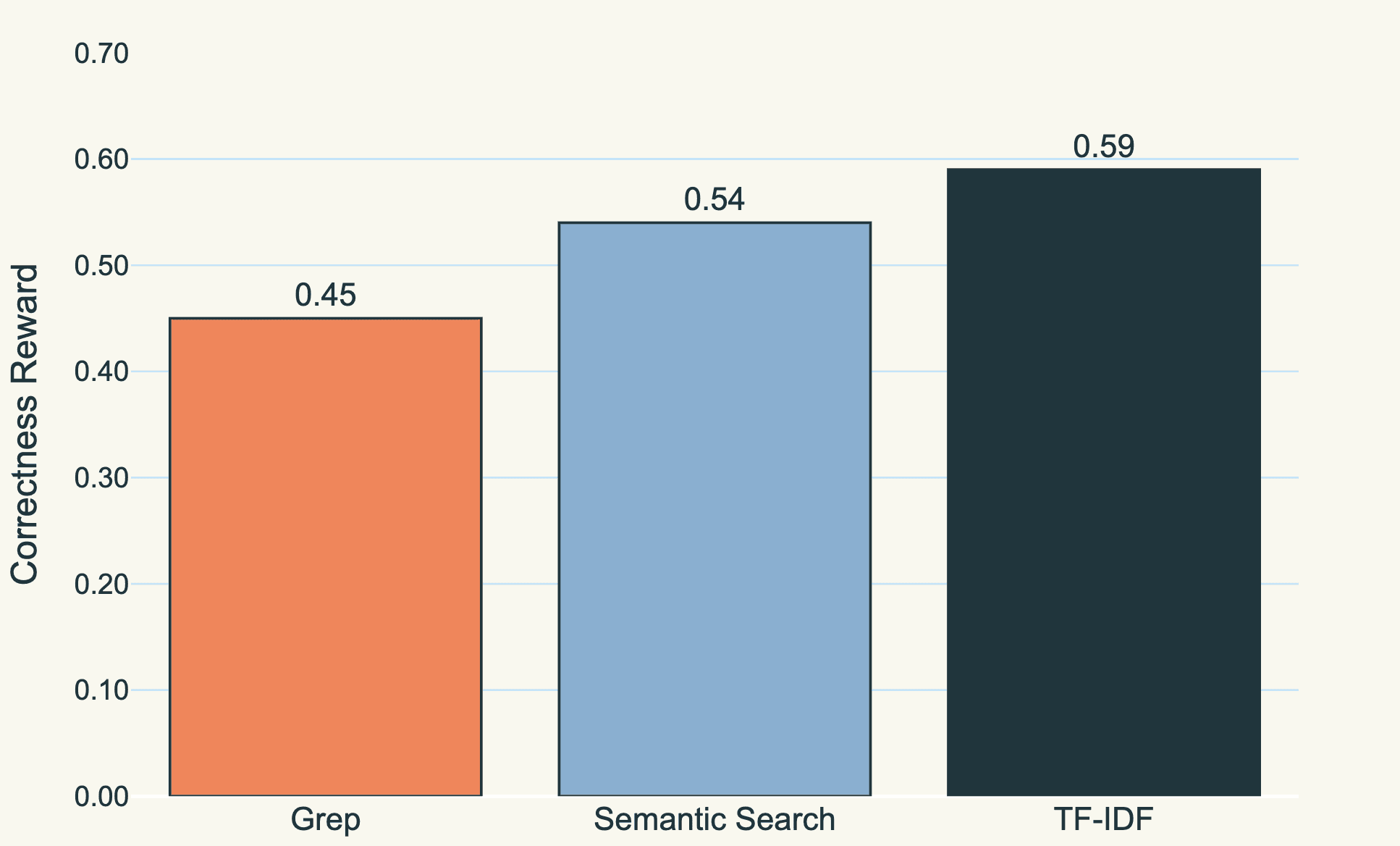
Comparison of different underlying search infrastructure for the search tool we provided Claude Sonnet 4.5. TF-IDF works the best out of the box, and is also the fastest in terms of combined execution and overall wall-clock time.
The real advantage becomes clear during RL training. TF-IDF gives you deterministic scoring, which means stable reward signals. Embeddings are too noisy, as small changes in the query can cause wild swings in the retrieved documents, making it nearly impossible for the model to learn consistent retrieval strategies. With pre-built and continuously updated TF-IDF indexes, we get sub-100ms searches even on massive knowledge bases while maintaining the flexibility to handle real-world query variations.
Of course, grep-based search tools are often much better for coding. Fortunately, the actual search mechanism is quite orthogonal from the rest of the pipeline; whatever you give the model, it will learn to optimize it. We will eventually allow customers to choose which search method they’d like the tool to use, and also provide recommendations based on the characteristics of their knowledge base.
Synthetic Data: The Zero-Shot Training Pipeline
The really cool part (at least to us) is that we generate all the training data synthetically. A customer drops in their knowledge base, and we automatically create a complete training dataset without needing any real user queries. This works because retrieval is fundamentally a verifiable task; there's deterministic ground truth for what should be retrieved for any given query.
The pipeline starts with raw markdown documents that get chunked into sections with deterministic chunk IDs. We filter these for quality ie checking word count, text quality scores, and detecting chunks that are mostly tables. For each high-quality chunk, we use frontier models to generate realistic customer questions that would be answered by that chunk. The key is using domain-specific example questions to guide the conversational style. Insurance questions sound different from healthcare questions, and the synthetic data needs to reflect that.
We then verify each synthetic question-answer pairs by actually running it through our search tool. If the target chunk ID appears in the top search results, we keep it. This verification loop ensures we're only training on examples where the search tool could plausibly find the right answer. The final dataset contains the synthetic question, the chunk ID as the answer, and the chunk content as reference text. This is, we emphasize, completely automated, with no human annotation required.
Training with AIPO and Partial Credit Rewards
We train these customer-specific models with rollouts using a token-level AIPO objective, optimizing for both retrieval accuracy and efficiency. The reward is composite: 90% weight on answer correctness and 10% on retrieval partial credit.
The retrieval partial credit reward scans all messages in the completion and parses any tool calls the model makes. If the target chunk ID appears anywhere in those search results (at any turn, even if the final answer is wrong) the rollout earns partial credit. This is especially helpful early in training because it provides learning signal before the model has reliably learned to compose answers from retrieved text. The model may issue multiple searches across 2–3 turns, and we consider results from all of them.
For the update, we use an off-policy REINFORCE estimator with clipped importance weights and leave-one-out advantages computed upstream. We typically sample K = 8 rollouts per prompt; for rollout (i), the advantage is the rollout’s reward minus the mean reward of the other (K-1) rollouts. To stabilize training, we (i) apply token-level AIPO clipping of the importance ratio, (ii) mask malformed tool-call spans via the loss mask, and (iii) optionally apply additional ratio safety (log-ratio clamp and masking of tokens/sequences outside configured bounds) and length normalization.
Formally, letting $\mu$ be the behavior policy that generated the rollout and $\pi$ the current policy, the (maximization) objective is
$$ \mathrm{J}_{\mathrm{AIPO}}(\theta) \frac{1}{\sum_{j=1}^{N}\sum_{i=1}^{G}\lvert y_i^{(j)}\rvert} \sum_{j=1}^{N} \sum_{i=1}^{G} \sum_{t=1}^{\lvert y_i^{(j)}\rvert} \min\Bigg( \underbrace{\frac{\pi\big(y^{(j)}_{i,t}\mid x_j, y^{(j)}_{i,<t}\big)}{\mu\big(y^{(j)}_{i,t}\mid x_j, y^{(j)}_{i,<t}\big)}}_{\text{importance ratio } r^{(j)}_{i,t}}, \delta \Bigg) \hat A^{(j)}_{i,t} $$
where $\hat A^{(j)}{i,t}$ is the token-level advantage and $\delta$ is the clipping threshold. With leave-one-out baselines,
$$ A_i = R(\tau_i)-\frac{1}{K-1}\sum_{k\neq i} R(\tau_k) $$
and in practice $\hat A^{(j)}_{i,t}$ denotes the per-token credit assignment for rollout (i) (optionally broadcast per sequence when using sequence-ratio variance reduction). We omit entropy and reference-KL terms from the objective; they are monitored as diagnostics only.
In practice, we typically use Qwen models up to 4B parameters for the search subagent, determined by the size and complexity of the knowledge base. Here, we show the reward curves for qwen3-4b over 200 steps, using a LoRA with rank 32.
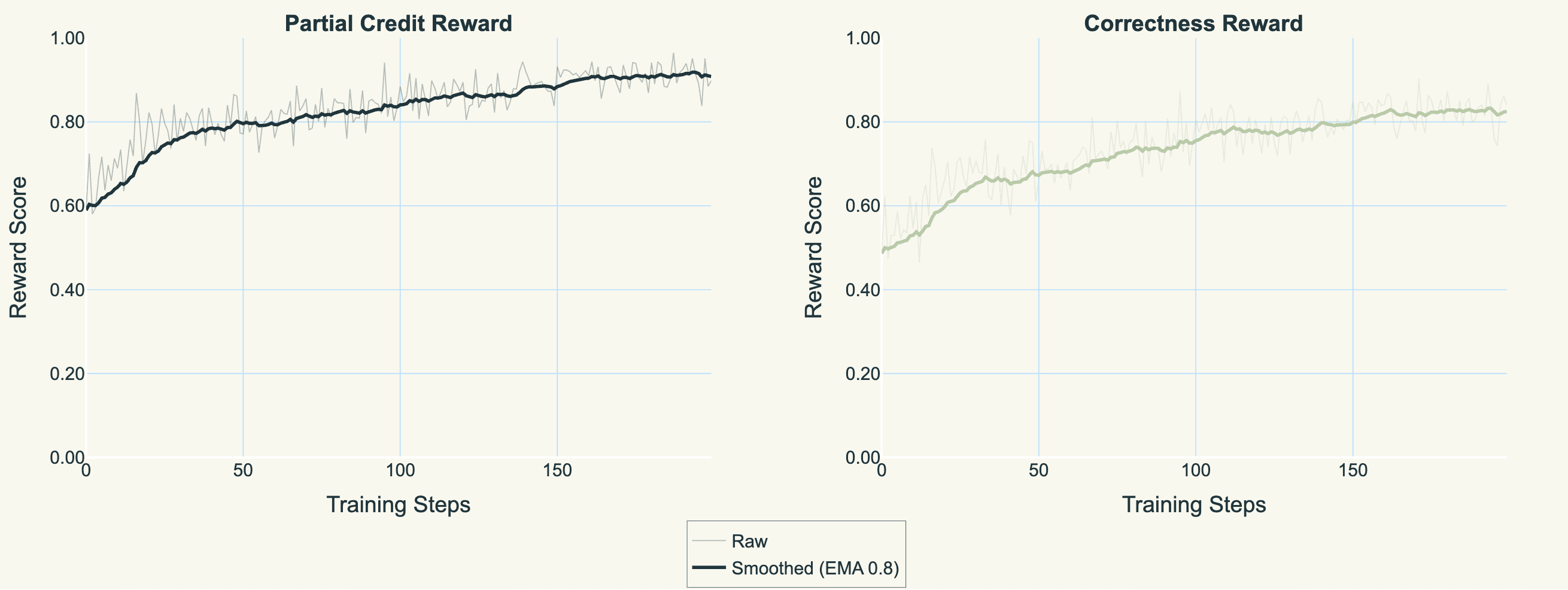
Reward curves for qwen3-4b on the insurance knowledge base.
Generalization: Models That Actually Learn the Domain
The most exciting result is that these models genuinely learn the structure and patterns of the knowledge base. When customers add new documents after training, the model maintains its performance without retraining. It has learned how insurance policies are structured, how clinical guidelines reference each other, how regulatory documents are organized, rather than memorized specific document-query pairs.
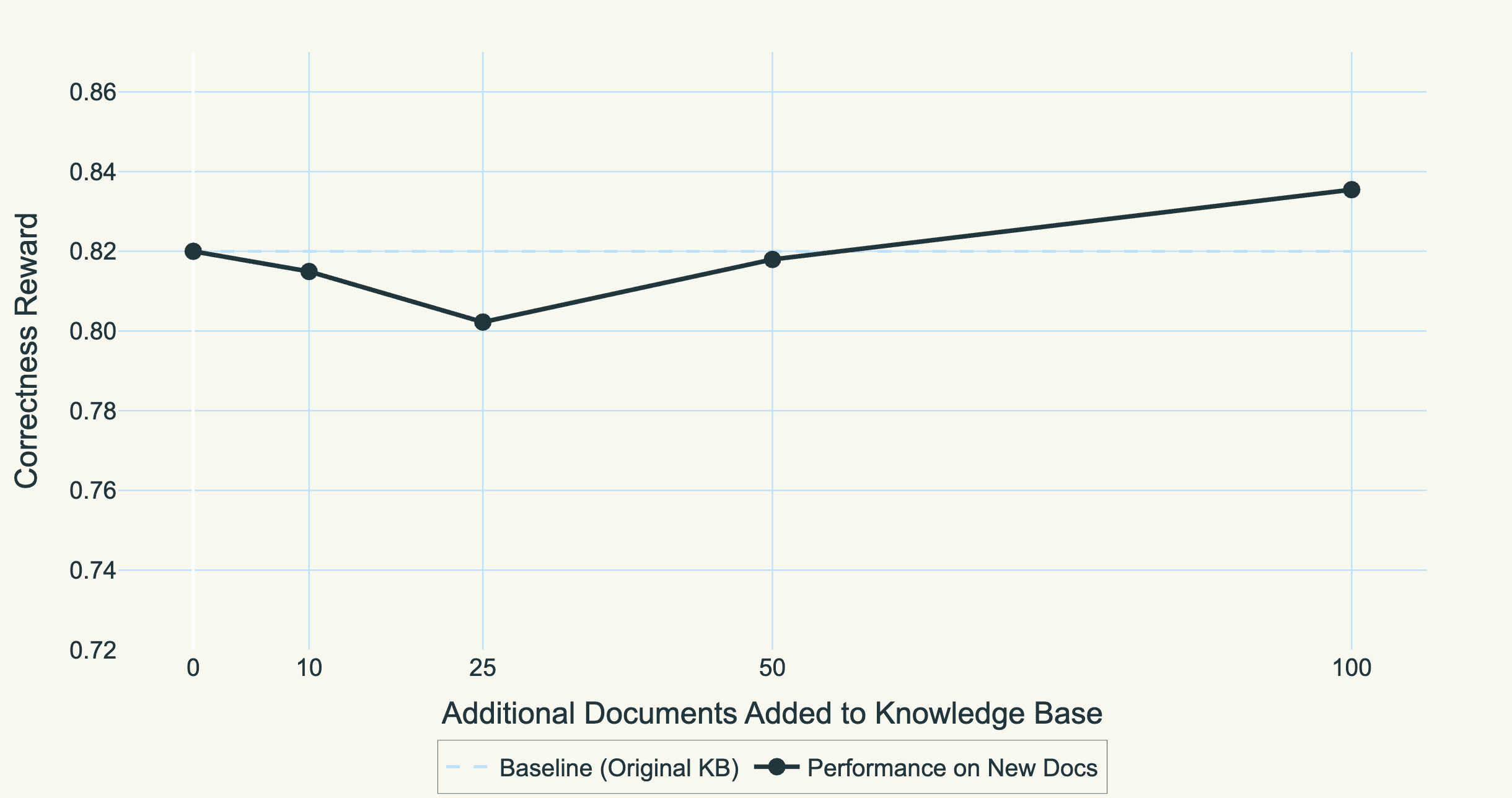
Trained model F1 score when we freeze the weights and simply test the F1 score with queries on documents not seen during training.
This generalization is what separates our approach from traditional fine-tuning. We're not teaching the model a mapping from questions to documents. We're teaching it to understand the domain itself, that is, the terminology, the document structures, the types of questions users ask, and how information is organized. Once it learns these patterns, it can apply them to new documents seamlessly.
Real-World Performance
On our internal insurance and healthcare evaluation sets, domain-specific Search Subagents achieve significantly higher partial and complete correctness scores on retrieval tasks, all while being significantly faster. Compare this to standard RAG at 0.42 F1, or GPT-4 with RAG at 0.61 F1 but taking 2.8 seconds. The speed matters as much as the accuracy e.g. when an insurance adjuster is on the phone with a claimant, they need answers in milliseconds, not seconds. We are currently optimising our Search Subagents with Baseten’s inference stack to run as quickly as possible, and will do full latency benchmarking in the future.
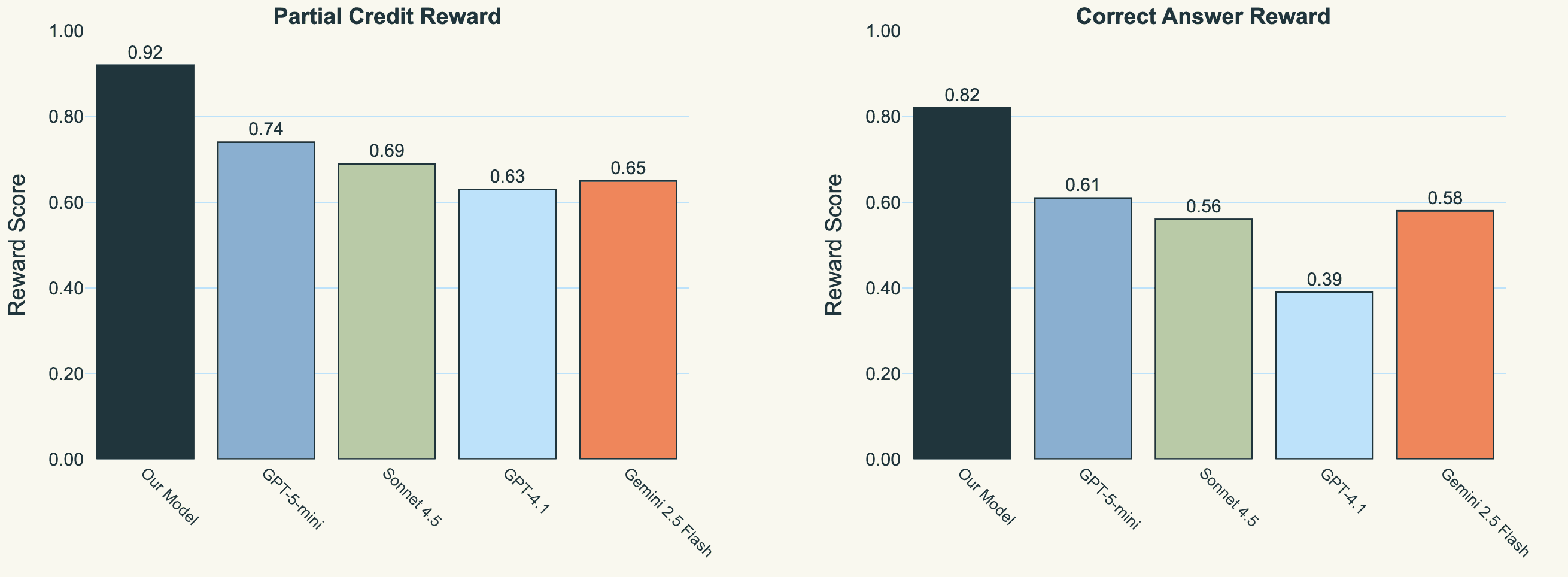
Performance of our final trained model on the insurance knowledge base compared with closed-source models given access to the same tool and instructions. Interestingly, our base model actually starts relatively on-par with some of the other models.
A major insurance provider deployed this across their page policy database. Previously, their support agents relied on fragile, static RAG systems searching through documents for specific exclusions or coverage details. Now they get precise answers with cross-references in under half a second. The model understands that when someone asks about “water damage in coastal properties with previous flood history,” they need the specific exclusion clause, the underwriting guidelines, and the claims history impact tables, which can all be retrieved in parallel in a single search.
Future Directions and Availability
We're exploring several extensions to make these models even more powerful. Adaptive parallelization would let models dynamically adjust their parallel search budget based on query complexity, where simple questions get one search, complex multi-part questions get many. This is already naively built into our pipeline but we want to make it more explicit in the reward functions. We also want to allow people to choose the backend of the search tool, as different search methodologies are sometimes more useful (ie grep for coding knowledge bases), and possibly even training the model to use different search methods simultaneously.
Search Subagents training is available now to existing Parsed customers and will be generally available in our platform in the coming weeks. The entire pipeline from knowledge base ingestion to trained model deployment is fully automated. What makes this particularly powerful is the true zero-shot nature; you literally just drop in your knowledge base, and we generate the synthetic training data, train the model with RL, and deploy a domain-specific search agent that intimately understands your documents. No real user queries, no manual annotation, just pure automated intelligence generation from your existing knowledge.
The combination of synthetic data generation, TF-IDF indexing, and GRPO training creates models that are fast, accurate, and most importantly, actually understand the domains they're searching. They're a fundamentally different approach from RAG to knowledge base search that learns and adapts to each customer's unique information architecture.