Case study
November 5, 2025
Purpose-built LLMs for dental note-taking
Frontier thinking model performance at a fraction of the latency.
Authors
Affiliations
Harry Partridge
Parsed
Charles O'Neill
Parsed
Dentists spend a surprising amount of time writing notes. It's one of those unsexy problems that affects thousands of practitioners daily—converting rambling patient conversations into structured clinical documentation.
Parsed has worked with a leader in the dental note-taking industry to create a purpose built, low latency model for dentists to use as an ambient scribe. This customer was initially interested in whether a smaller, more efficient model could be used to perform a single task: producing structured dental notes from a raw transcript. These transcripts were up to 25000 tokens long, and involved complex examination and treatment procedures. Subsequently, they were also interested in whether the same model could be used for another two tasks: real time note taking and note alteration. This resulted in three distinct tasks for our model to perform
Task 1: Convert ambient transcripts into structured clinical notes
Task 2: In real time, add new findings to existing notes as procedures unfold
Task 3: Alter existing notes and enhance their quality
Remarkably, our model learned all three tasks simultaneously within a single LoRA adapter (rank 256), whilst still handling specialized dental terminology, multiple tooth notation systems and long, complex transcripts.
We eventually deployed a fine-tuned model that matches gemini-2.5-pro's accuracy while responding 5-6x faster, on three different tasks with the one model. For real-time updates, we achieved performance that surpasses all other models by significant margins, all while handling domain-specific complexity that breaks general-purpose LLMs.
Building Evaluators That Know What Good Looks Like
Rather than guessing what good looks like, we built comprehensive evaluation frameworks using Lumina, our adaptive evaluation engine that learns to judge like domain experts.
Using Lumina, we analyzed thousands of outputs from models across the capability spectrum—from Llama-3-8B to GPT-5. This allows us to catalogue exactly why each model failed, and partition all the errors into semantically related checks.
The patterns that emerged were interesting. In addition to the usual LLM errors involving hallucination and omission of key information, we identified a number of errors unique to this customer’s specific task. We observed that models would identify clinical findings correctly but place them in the wrong section. They'd use dental terminology that demonstrated a misunderstanding of the details of a given situation. They'd confuse tooth notation systems in predictable ways.
We turned these failure modes into six binary evaluators:
Clinical terminology: Does the note use all appropriate terminology, as if an expert dentist wrote it?
Contradictions: Any conflicting statements?
Information completeness: Did we omit any key details from the transcript?
Source fidelity: Did we add anything that wasn't there? Were there any hallucinations?
Structural compliance: Right format, right sections?
Tooth notation: Did we get the teeth right?
Training with Iterative SFT: From Good to Perfect
With robust evaluators in place, we employed iterative SFT (iSFT) to train our model. This is a technique that makes use of the full reasoning from LLM-as-a-judge evaluations, leading to faster and cheaper training when compared to RL, which only utilizes the numeric judgements.
The iSFT Process for Clinical Notes
For each of our 30,000 training examples:
Generate: Model produces initial clinical note from transcript
Evaluate: Lumina evaluators identify specific failures (e.g., “incorrect tooth notation in paragraph 3”)
Refine: Model repairs its output based on structured feedback
Iterate: Repeat until all six evaluators pass
Train: Use these perfect outputs for supervised fine-tuning
This process is fundamentally different from standard distillation. Instead of training on "what GPT-5 would say," we train on outputs that achieve a higher evaluation score than even GPT5, raising the ceiling for downstream performance.
The information-theoretic advantage of iSFT is quite clear. While standard RL provides O(1) bits of information per example (a scalar reward), iSFT provides O(T) bits—dense, token-level supervision across thousands of tokens. This translates to:
6-7x better sample efficiency than standard SFT
10x fewer LLM evaluator calls than rejection sampling
Monotonic improvement with more data (no plateau from noisy examples)
Solving Domain-Specific Challenges: Synthetic Data Generation
In order to give dentists maximal control over their notes, this customer also allowed dentists to specify the type of tooth notation to be used in the output. The dentists were able to choose from one of 4 possible notation systems: Palmer, FDI, UNS, Victor Haderup. The information about these notation systems on the internet is quite rare and inconsistent - many online websites have conflicting recommendations about how to apply these notation systems, particularly for baby teeth and for the Victor Haderup notation system which are less common. This means that by default, only slow reasoning models can consistently use these notation systems in the way desired by the dental scribe - non-thinking frontier models do not understand the notation at an intuitive level.
This scribe provided us with a short (<200 word) paragraph, describing exactly how they wanted the model to use all of the four notation systems. We initially tried simply placing these descriptions into the prompt, but found that even with frontier non-thinking models like GPT-4.1 and Claude-Sonnet-4.5, generated notes would often contain errors. In practice, this would waste dentists time and potentially leading to incorrect documentation for patients. It was therefore clear that the only possible way to get the desired performance out of a non-thinking model was to train a better model. However, simply running fine-tuning on this 200 word paragraph is not sufficient to ingrain this knowledge into the model.
The only remaining solution was to use synthetic data generation. However, traditional synthetic data generation hits an entropy ceiling quickly. If you repeatedly ask a model for questions about a 200-word description, and you'll get maybe 20-30 unique patterns before it starts recycling. This is the fundamental problem Andrej Karpathy highlighted recently on the Dwarkesh podcast: LLMs have surprisingly low entropy relative to their training corpus.
We employed a simple new approach to break this entropy ceiling. Instead of directly generating synthetic samples from the original text, we first perform transformations (rephrasing, restructuring, reformatting) of the source. By performing these mutations multiple times, we can continually increase the diversity of the formulation of the source information. We then use these restructured versions of the source text to generate tasks for the model to perform, and then use the original source text to synthetically produce the desired response for a given task. This dramatically increases the entropy of downstream synthetic examples, allowing us to generate over 50,000 training examples across four distinct task categories. These tasks included
Translation:
Translation from one notation system to another. This produces only a limited number of training examples, as there are only so many unique combinations of teeth to translate between. It is also somewhat synthetic, and doesn’t translate as well to real world usage.
Translation from natural language to any tooth notation system. This is more aligned with what the model will be required to do in production. To generate a large and diverse set of natural language tooth descriptions, we seeded with a small set of example natural language phrases like ‘bottom right incisor’ or ‘molar on the upper left side’, and then began to sample from the model. We sampled from a range of frontier models and randomly selected from already sampled phrases to create new seeds which we could use to generate more phrases. This resulted in over 1000 natural language tooth descriptions, ranging from “The tooth adjacent to the midline on the upper jaw, on the right” to “A deciduous first molar on the upper right side”
In both scenarios, the correct answers were generated by a model with the source information in context. However, the training example then requires the model to produce the correct answers without seeing the ground truth information. This forces the model to internalize this information.
Exam-style questions
Using branched synthetic data generation, we generated a large range of factual exam-style questions. We then used a model with the original ground truth information in context to provide grounded answers to these questions. This forms question answer pairs which are then used to train the model to respond with correct information even when the source text is not in context.
Scenario-based questions
We generated a set of scenarios involving a person with questions about the various tooth notation systems. We then used a model with the source information in context to generate ground truth responses to these scenario-based questions, producing more training examples.
Summarization
Lastly, we generated a set of summary documents which had a range of practical examples and descriptions of the tooth notation systems. We paired these with a small set of predefined questions asking for a summary of the various tooth notation systems.
It is often remarked that humans are able to gain a full understanding of a topic by reading a single paragraph of text, whereas LLM training requires copious amounts of data. However, in this process, we demonstrate that with intelligent synthetic data generation, it is in fact possible to achieve the same level of source data efficiency with LLMs. Indeed, the resulting model achieved 90% accuracy on the tooth notation evaluation - matching the much slower gemini-2.5-pro. This process is completely generalizable, and can allow us to embed domain specific knowledge into any model.
Results
For the summarization task (i.e. writing a clinical note), our model achieves similar performance to gemini-2.5-pro with maximum thinking. We’re about 10% better than gemini-2.5-pro with minimum thinking, and significantly better than gemini-2.5-flash, o4-mini and gpt-4o-mini.
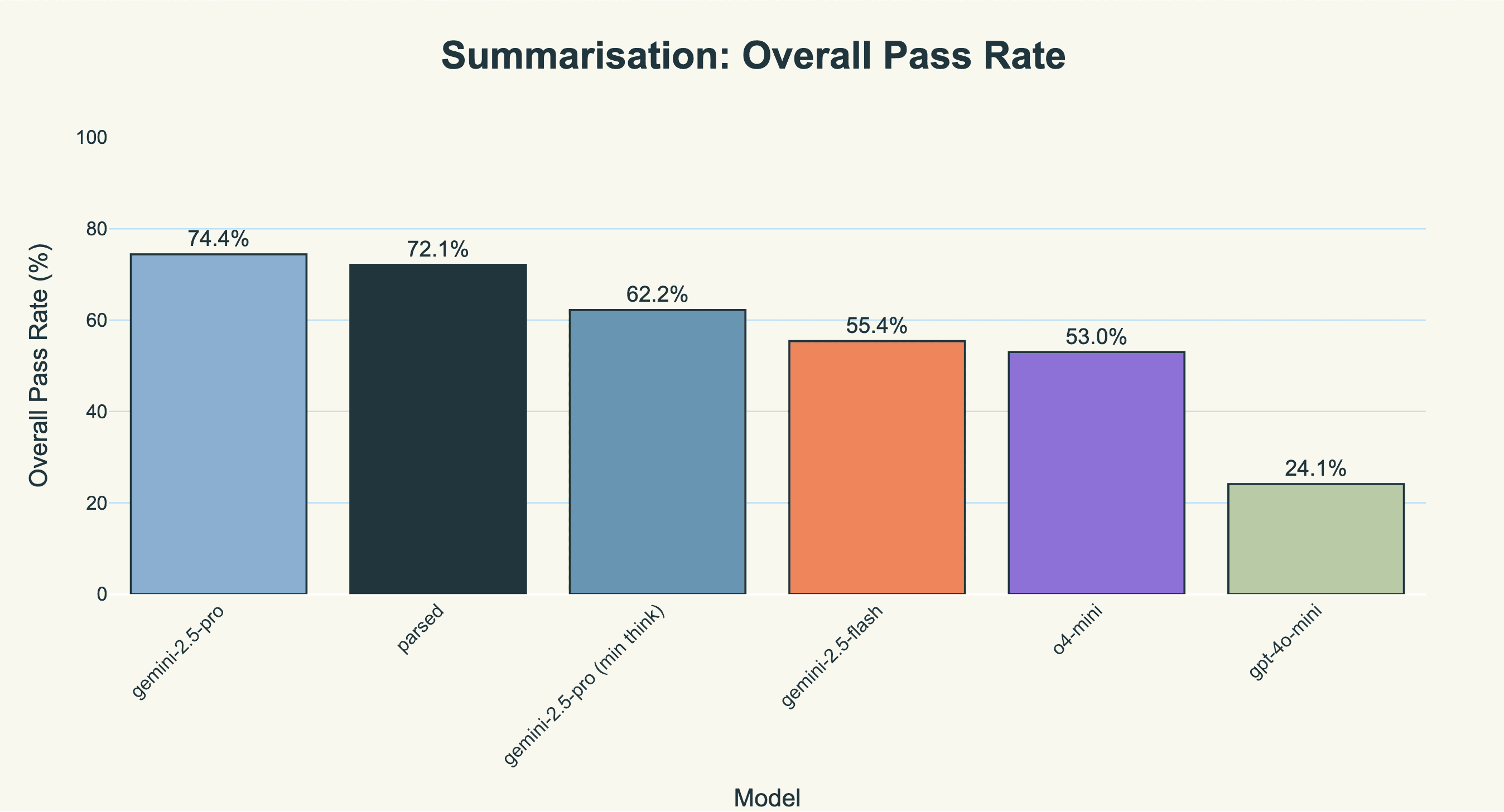
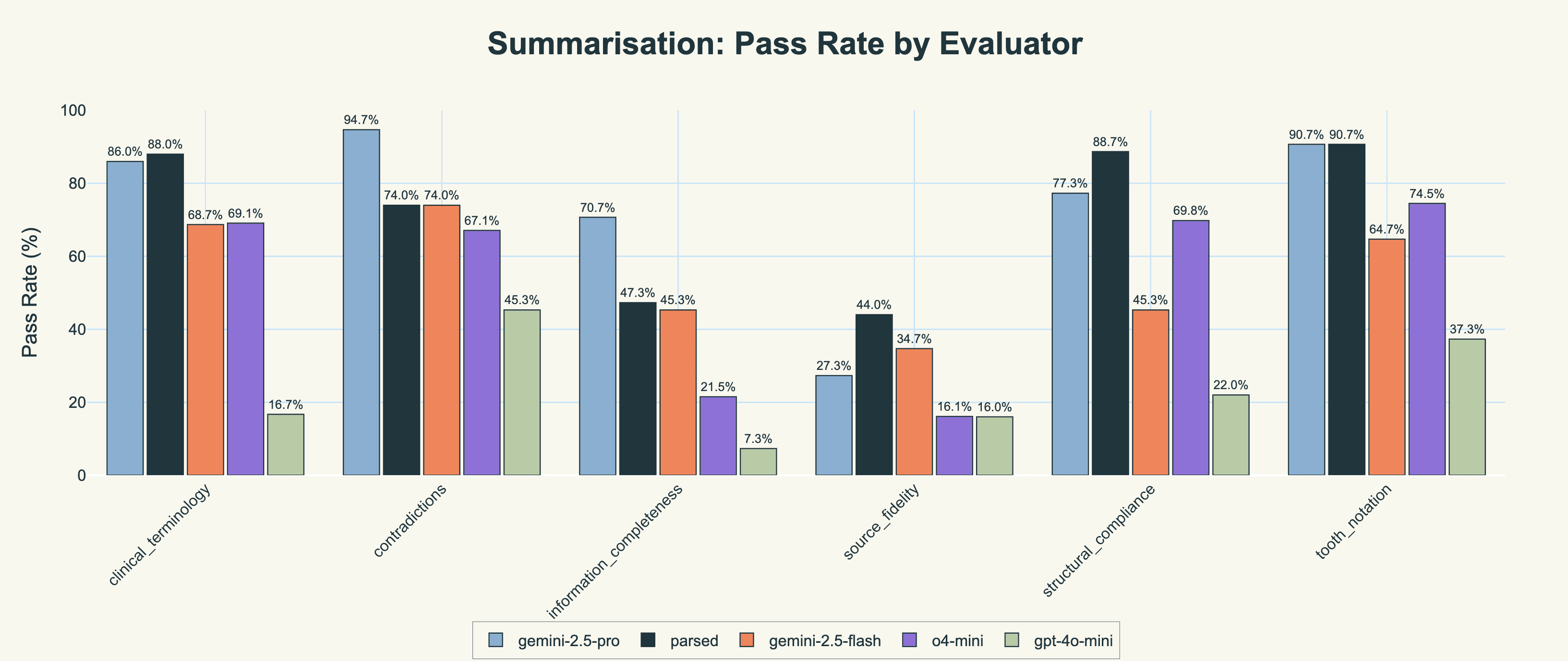
For the sake of completeness, we include the evaluation results across all six evaluators.
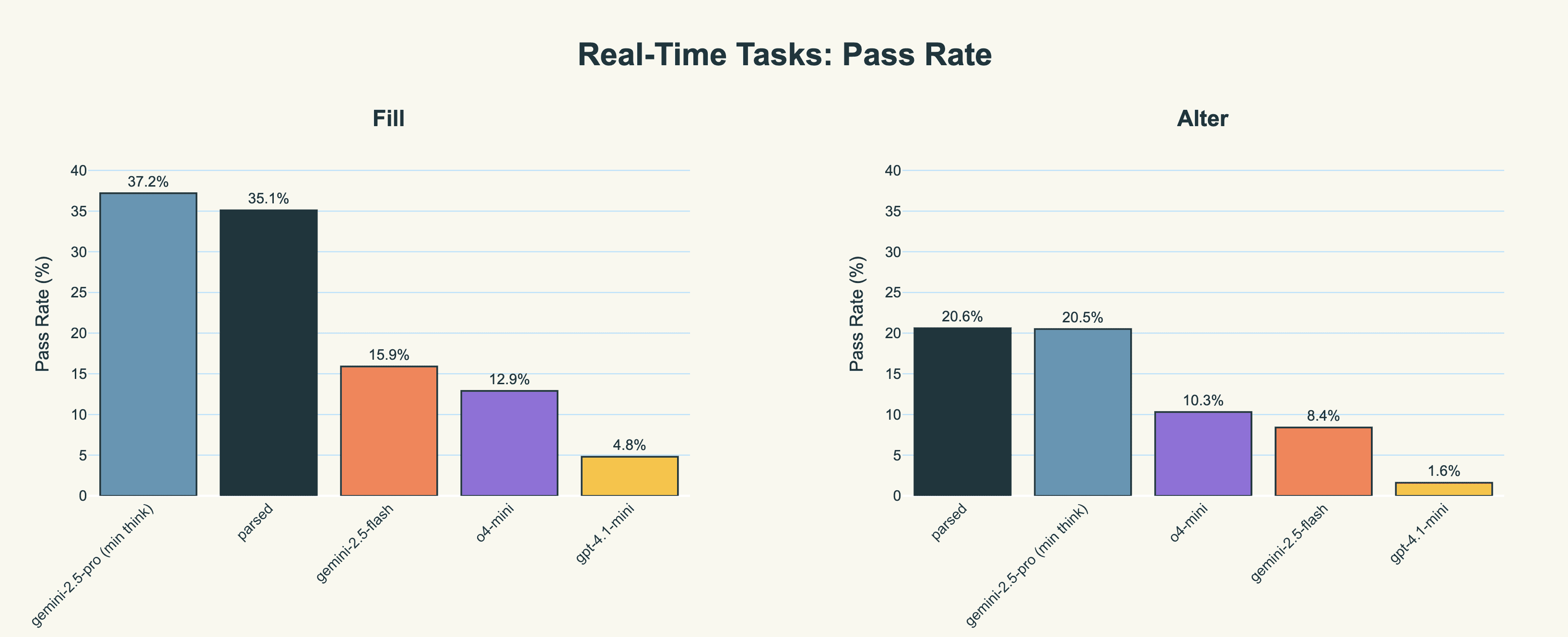
For the real-time tasks, the main benchmark is gemini-2.5-pro with minimum thinking, which is the baseline as using significant thinking budgets is ruled out by having a task with such low latency requirements. We perform similarly to gemini-2.5-pro, and outperform gemini-2.5-flash (500 thinking tokens; what was previously being used by the scribe), o4-mini and gpt-4.1-mini by a long way.
Latency
However, absolute performance is not the only axis along which a customer must optimize. Most customers also have preferences for how much latency they’re willing to accept (some even have hard constraints on these). For this dental scribe, we managed significant speedups over closed-source models.
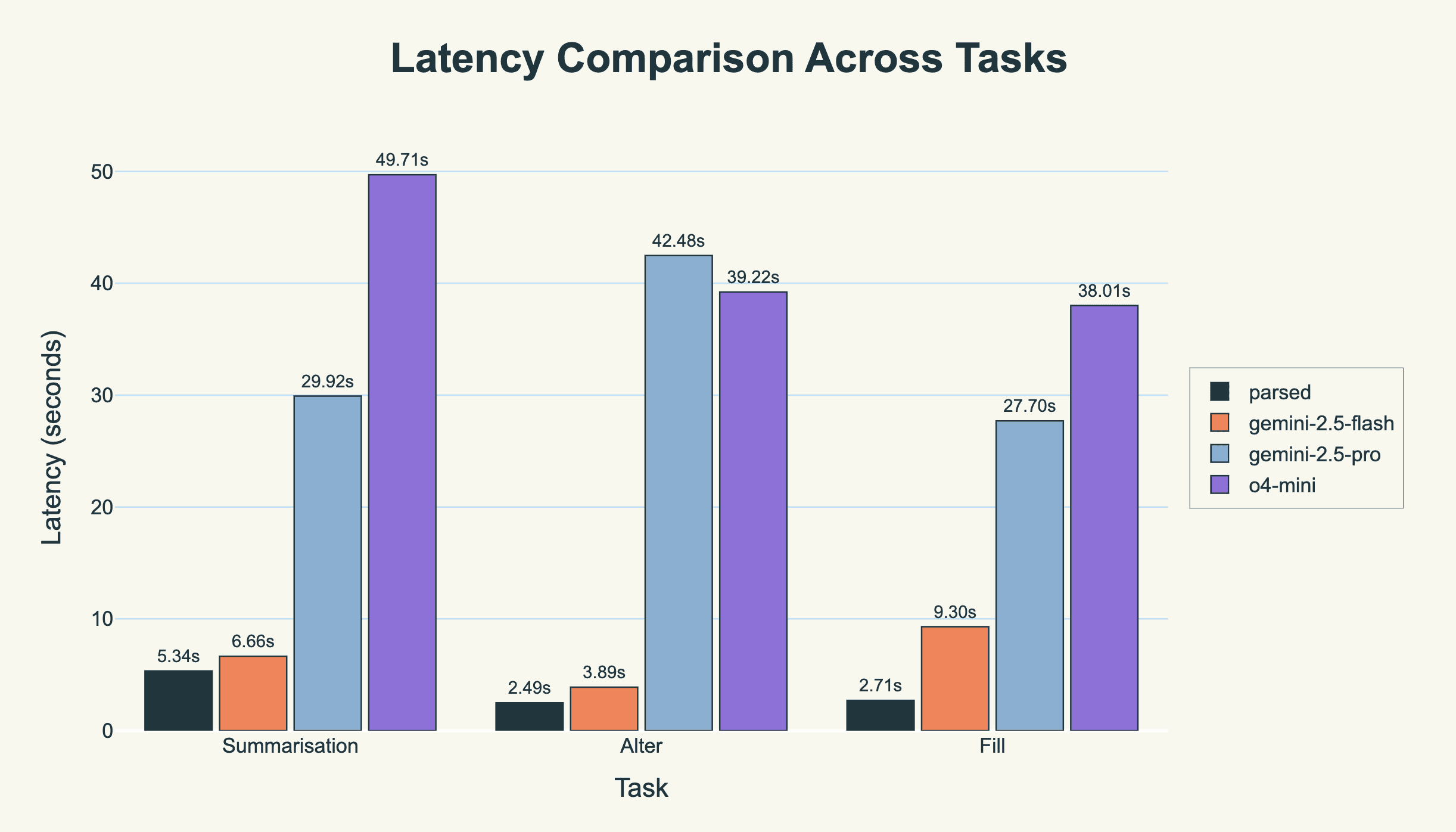
Absolute latency across tasks. parsed is around 5-6 times faster than gemini-2.5-pro!
Importantly, we manage these speedups while consistently being the best model.
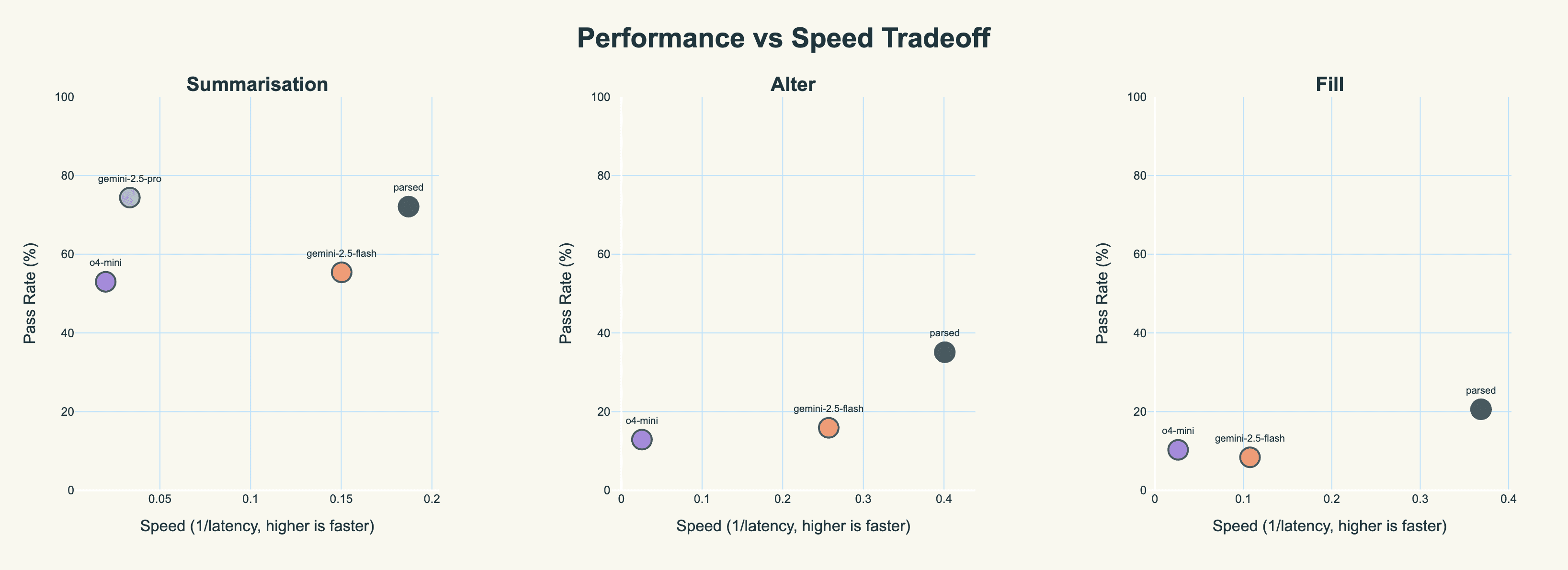
Performance (mean pass rate on all six evaluators) vs speed (1/latency, higher is faster).
Why Evaluation-Driven Development Wins
Three insights from this project:
Evaluation quality sets your ceiling. Without comprehensive evaluators, you can't distinguish between outputs that look good and outputs that are actually good. Our six evaluators define what excellence means in dental documentation.
Dense feedback beats sparse rewards. Where RL provides one bit per example, iSFT delivers token-level corrections. This information density is why we achieve frontier performance with a fraction of the compute.
Fine-tuning is compatible with extreme data efficiency. With intelligent synthetic data generation, we can teach the model to fully internalize even a very small amount of source information.
Specialization works. Our model handles three distinct tasks because we clearly specified success for each. General models struggle with multi-task learning because they're optimizing for everything and excelling at nothing.
Conclusion
This project exemplifies our development methodology: build evaluators that understand domain quality, then train models to excel against those standards. For regulated industries like healthcare, this evaluation-first approach delivers what prompt engineering never could: specialized models that outperform general-purpose systems at a fraction of the cost and latency.
The future of production AI isn't one model doing everything. It's building the right evaluation framework, then training a model that excels against it. For clinical documentation, we've shown this works. The approach generalizes to any domain where accuracy matters more than generality.